Pulsar 是一个开源的分布式消息队列产品,最早是由 Yahoo 开发,现在是 Apache 基金会旗下的开源项目。
架构设计与实现
系统架构
无论是 RocketMQ、RabbitMQ 还是 Kafka,消息都是存储在 Broker 的磁盘或者内存中。客户端在访问某个主题分区之前,必须先找到这个分区所在 Broker,然后连接到这个 Broker 上进行生产和消费。
在集群模式下,为了避免单点故障导致丢消息,Broker 在保存消息的时候,必须也把消息复制到其他的 Broker 上。当某个 Broker 节点故障的时候,并不是集群中任意一个节点都能替代这个故障的节点,只有那些“和这个故障节点拥有相同数据的节点”才能替代这个故障的节点。原因就是,每一个 Broker 存储的消息数据是不一样的,或者说,每个节点上都存储了状态(数据)。这种节点称为“有状态的节点(Stateful Node)”。
Pulsar 与其他消息队列在架构上,最大的不同在于,它的 Broker 是无状态的(Stateless),即在 Broker 中既不保存元数据,也不存储消息。
基于计算存储分离的思想设计的架构,分为计算层和存储层两层,即计算层的 Broker 集群和存储层的 BookKeeper 集群两部分。
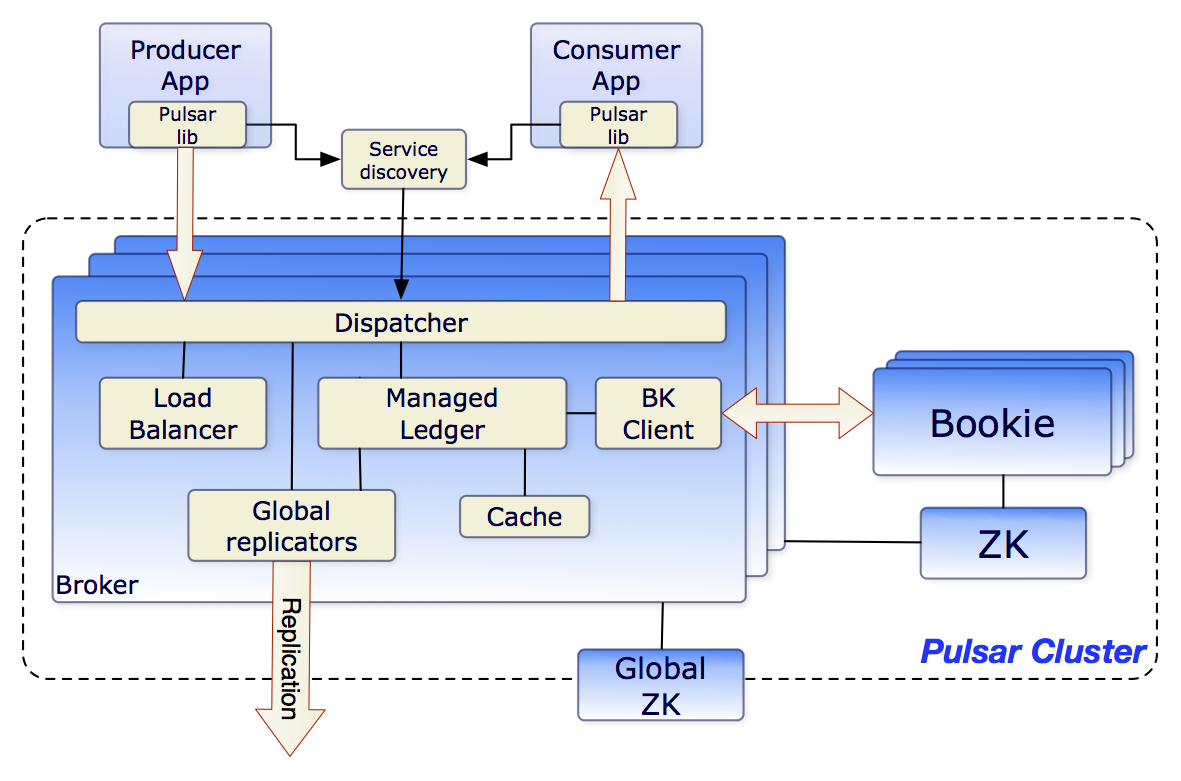
- ZooKeeper 集群:存储元数据。
- BookKeeper:存储消息数据。有点儿类似 HDFS,是一个分布式的存储集群,只不过它的存储单元和 HDFS 不一样,在 HDFS 中存储单元就是文件,而 BookKeeper 的存储单元是 Ledger。Ledger 是一段 WAL(Write Ahead Log),简单地理解为某个主题队列的一段,它包含了连续的若干条消息,消息在 Ledger 中称为 Entry。为了保证 Ledger 中的 Entry 的严格顺序,Pulsar 为 Ledger 增加一次性的写入限制,Broker 创建一个 Ledger 后,只有这个 Broker 可以往 Ledger 中写入 Entry,一旦 Ledger 关闭后,无论是 Broker 主动关闭,还是因为 Broker 宕机异常关闭,这个 Ledger 就永远只能读取不能写入了。如果需要继续写入 Entry,只能新建另外一个 Ledger。“一次性写入”的主要目的是为了解决并发写入控制的问题。对于共享资源数据的并发写一般都是需要加锁的,否则很难保证数据的一致性。对于分布式存储来说,就需要加“分布式锁”。但分布式锁本身就很难实现,使用分布式锁对性能也会有比较大的损失。这种“一次性写入”的设计,只有创建 Ledger 的进程可以写入数据,Ledger 这个资源不共享,也就不需要加锁。
- LoadBalancer:负责动态的分配,哪些 Broker 管理哪些主题分区。
- Managed Ledger:负责管理本节点需要用到的那些 Ledger,这些 Ledger 都是保存在 BookKeeper 集群中的。
- Cache:来缓存一部分 Ledger,提升性能。
Pulsar 的客户端要读写某个主题分区上的数据之前,依然要在元数据中找到分区当前所在的那个 Broker,这一点是和其他消息队列的实现是一样的。不一样的地方是,其他的消息队列,分区与 Broker 的对应关系是相对稳定的,只要不发生故障,这个关系是不会变的。而在 Pulsar 中,这个对应关系是动态的,它可以根据 Broker 的负载情况进行动态调整,而且由于 Broker 是无状态的,分区可以调整到集群中任意一个 Broker 上,这个负载均衡策略就可以做得非常简单并且灵活。如果某一个 Broker 发生故障,可以立即用任何一个 Broker 来替代它。
客户端在收发消息之前,需要先连接 Service Discovery 模块,获取当前主题分区与 Broker 的对应关系,然后再连接到相应 Broker 上进行消息收发。客户端收发消息的整体流程,和其他的消息队列差不多。比较显著的一个区别就是,消息是保存在 BookKeeper 集群中的,而不是本机上。数据的可靠性保证也是 BookKeeper 集群提供的,所以 Broker 就不需要再往其他的 Broker 上复制消息了。
协议和网络层
协议
Broker 的协议是自定义的私有协议。协议的格式是以行格式解析,即自定义的编解码格式。
整体协议是行格式的自定义编解码,但是协议中的命令(Command)和部分元数据是用 Protobuf 组织来表示。
网络层
基于 Netty 框架开发实现。
数据存储
元数据存储
元数据存储的核心是 ZooKeeper。最新版本的内核支持可插拔的元数据存储框架,即支持将元数据存储到多种第三方存储引擎,比如 etcd、本地内存、RocksDB 等。
消息数据
在计算层,不负责消息存储,调用 BookKeeper 的 SDK,往 BookKeeper 写入数据。
在 Broker,消息数据的存储是以分区维度组织的,即一个分区一份文件。在实际的存储中,分区的数据是以一段一段 Ledger 的形式组织的,不同的 Ledger 会存储到不同的 Bookie 上。每段 Ledger 包含一批 Entry,一个 Entry 为一条消息。
在 Broker 中,消息会先以 Entry 的形式追加写入到 Ledger 中,一个分区同一时刻只有一个 Ledger 处于可写状态。当写入一条新数据时,会先找到当前可用的 Ledger,然后写入消息。当 Ledger 的长度或 Entry 个数超过阈值时,新消息会存储到新的 Ledger 中。一个 Ledger 会根据 Broker 指定的 QW 数量,存储到多个不同的 Bookie 中。一个 Bookie 可以存放多个不连续的 Ledger。
当一台 Bookie(节点)的负载高了或者容量满了后,就禁用该台节点的写入,将负载快速转移到其他节点上,从而实现存储的弹性。消息数据本质上就是分段存储的。
在写入性能方面,Broker 不太关注实际的写入性能的提升,性能主要依赖 BookKeeper 的性能优化。BookKeeper 在底层会通过 WAL 机制、批量写、写缓存的形式来提高写入的性能。
提供了 TTL 和 Retention 机制来支持消息删除。
- TTL 策略:消息在指定时间内没有被用户 ACK 掉时,会被 Broker 主动 ACK 掉,ACK 操作不涉及数据删除。
- Retention 策略:消息被 ACK 之后(消费者 ACK 或者 TTL ACK)继续在 Bookie 侧保留的时间,消息被 ACK 之后就归属于 Retention 策略,即在 BookKeeper 保留一定时间。Retention 以 Ledger 为最小操作单元,删除即是删除整个 Ledger。
TTL 仅用于 ACK 掉在 TTL 范围内应被 ACK 的消息,不执行删除操作。真正删除的操作是依靠 Retention 策略来执行的。
生产者和消费者
客户端在进行生产消费之前,需先进行客户端寻址操作。通过寻址找到 Topic 分区所在的 Leader 节点,然后连接上节点进行生产消费。支持通过 Pulsar 协议和 HTTP 协议两种形式来完成寻址操作。
生产端
访问模式
一个分区在同一时间支持怎样的生产者以何种方式写入。比如一个分区同一时间是所有生产者都可以写,还是只有一个生产者可以写,或者多个生产者灾备写。在其他消息队列中,一般都是默认所有的生产者可以写。
- Shared:允许多个生产者将消息写入到同一个 Topic。
- Exclusive:只有一个生产者可以将消息写入到 Topic,当其他生产者尝试写入消息到这个 Topic 时,会发生错误。
- WaitForExclusive:只有一个生产者可以将消息发送到 Topic,其他生产者连接会被挂起而不会产生错误,类似 ZooKeeper 的观察者模式。
路由模式
- RoundRobinPartition(轮询):当消息没有指定 Key 时,生产者以轮询方式将消息写入到所有分区
- SinglePartition(随机选择分区):当消息没有指定 Key,生产者会随机选择一个分区,并将所有消息写到这个分区。针对上述这两种策略,如果消息指定了 Key,分区生产者会优先根据 Key 的 Hash 值将该消息分配到对应的分区。
- CustomPartition(自定义):用户可以创建自定义路由模式,通过实现 MessageRouter 接口来自定义路由规则。
语义
支持 Batch 语义,即支持批量发送。启用批量处理后,生产者会在客户端累积并发送一批消息。批量处理时的消息数量,取决于最大可发送消息数和最大发布延迟。
写入模式
支持同步写入、异步写入两种方式。
消费端
消费模型
主要支持 Pull,即由客户端主动从服务端 Pull 数据来支持消费。
订阅维度
支持消息和分区两个维度,即可以将整个分区绑定给某个消费者,也可以将分区中的消息投递给不同的消费者。
订阅类型
- 独占:一个订阅只可以与一个消费者关联,只有这个消费者能接收到 Topic 的全部消息,如果这个消费者故障了就会停止消费。
- 灾备:一个订阅可以与多个消费者关联,但只有一个消费者会消费到数据,当该消费者故障时,由另一个消费者来继续消费。
- 共享:一个订阅可以与多个消费者关联,消息会通过轮询机制发送给不同的消费者。
- Key 共享:一个订阅可以与多个消费者关联,消息根据给定的映射规则,相同 Key 的消息由同一个消费者消费。
订阅模式
持久化和非持久。核心区别在于,游标是否是持久化存储。如果是持久化的存储,当 Broker 重启后还可以保留游标进度,否则游标就会丢失。
消费确认
提交当前消费的进度,即提交游标的进度,提供了累积确认和单条确认两种模式。
- 累积确认:消费者只需要确认收到的最后一条消息,在此之前的消息,都不会被再次发送给消费者;
- 单条确认指消费者需要确认每条消息并发送 ACK 给 Broker。
如果希望保存消费进度,那么就需要选择持久化订阅。如果是为了提高 ACK 性能,就需要选择累积确认。
在实际运行过程中,Puslar 的单条 ACK 机制给 Broker 带来了蛮大的挑战。因为允许客户端一条一条 ACK 数据,就会造成某些数据一直不被 ACK,从而造成消息空洞的现象。
同时也提供了取消确认的功能。即当某些消息已经被确认,已经消费不到数据了,此时如果还想消费到数据,就要通过客户端发送取消确认的命令,使其可以再消费到这条数据。
取消确认操作支持单条和批量,不过这两种操作方式在不同订阅类型中的支持情况是不一样的。
HTTP 协议支持和管控操作
在访问层面,Pulsar 的管控操作和生产消费数据流操作是分开支持的。即数据流走的是自定义协议通信,管控走的是 HTTP 协议形式的访问。从访问上就隔离了管控和数据流操作,在后续的权限管理、客户端访问等方面提供了很多便利。
HTTP 协议的端口和私有协议的端口是独立的,内核中启动了一个单独的 HTTP Server 来提供服务。在代码上可以通过 HTTP Rest 的 API 直接进行管控操作。命令行 CLI 的底层也是通过 HTTP Client 发起访问的,用 HTTP 的好处就是,不需要单独在二进制协议、服务端接口、客户端 SDK 方面单独进行管控的支持。
在 HTTP Rest 接口中,同时提供了简单的生产接口和消费接口,即可以通过 HTTP 协议进行数据的写入和消费,但这个功能不建议用在现网的大流量的业务中。如果需要支持 HTTP 协议的生产和消费,有些商业化的产品是可以支持的,底层技术层面走的还是 Proxy 的方案。
集群构建
集群构建和元数据存储的核心依旧是 ZooKeeper,同时社区也支持了弱 ZooKeeper 化改造。
Broker 启动时会在 ZooKeeper 上的对应目录创建名称为 BrokerIP + Port 的子节点,并在这个子节点上存储 Broker 相关信息,从而完成节点注册。
全部元数据都持久化存储在 ZooKeeper 中,同时 Broker 也会缓存一部分数据。在 ZooKeeper 中主要存储了包括集群管控,存储层的 Bookie、Ledgers,计算层 LoadBalance、Bundle,周边功能 Schema、Stream、Function 等信息。
主节点
负责管理集群的元数据和状态信息,例如主题、订阅、消费者等。主节点还负责协调集群中的各个节点,例如选举副本、分配分区等。
当一个节点启动时,它会向 ZooKeeper 注册自己,并尝试成为主节点。如果当前没有主节点,或者当前的主节点失效了,那么该节点就会成为新的主节点。如果多个节点同时尝试成为主节点,那么它们会通过 ZooKeeper 的选举机制来进行竞争,依赖 ZooKeeper 的存储和 Watch 来实现分布式协调,最终只有一个节点会成为主节点。
弱 ZooKeeper 实现
Zookeeper 集群本身存在性能和容量限制,因为在底层的存储数据结构是分层树结构。分层树结构在读取时需要多层检索,从而导致数据如果存储在硬盘,读取性能会很低。因此只有将所有数据加载到内存中,才能提供较好的性能。
此时单个节点可承载的容量上限,就是集群所能承载的容量上限。而 Pulsar 存算分离架构和计算层弹性需要存储很多元数据,所以 ZooKeeper 就成为了瓶颈。
弱 ZooKeeper 就是允许将 ZooKeeper 替换为其他的单机或分布式协调服务。目前支持 ZooKeeper、etcd、RocksDB、内存四种方案。
- 基于 etcd 的方案是当前集群化部署的推荐方案。etcd 底层存储是 B 树的结构,在硬盘层面的读取性能较高,不一定要把数据加载到内存中,所以存储容量不受单机的限制。
- 基于 RocksDB 的方案和 RabbitMQ 的 Mnesia 大致上是一个思路,都是基于节点层面的存储引擎来完成元数据的存储。RocksDB 的方案主要用在单机模式上,主要原因是 RocksDB 是一个单机数据库。
- 基于内存的方案主要用在集成测试的场景中。
数据可靠性
通过 Ledger 多副本实现。通过在 Broker 中设置 Qw 和 Qa 来设置 Ledger 的总副本数和写入成功的副本数。所以从一致性来看,既可以是强一致,也可以是最终一致。
每条消息是一个 Entry ,一批 Entry 组成一个 Ledger ,一批 Ledger 组成一个分区。 所以当数据不断写入分区时,Broker 会根据条件来不停地创建分区维度的 Ledger。这个条件通常是 Ledger 的固定长度,另外当 Ledger 写入流断开时,也会创建新的 Ledger。所以,在 Ledger 创建时就会根据设置的 Qw 数量,在 多个 Bookie 中创建 Ledger。
通过配置机架感知(RackawareEnsemblePlacementPolicy)、区域感知(RegionAwareEnsemblePlacementPolicy)、可用区感知(ZoneawareEnsemblePlacementPolicy)3 种集成放置策略,来控制 Ledger 在 BookKeeper 多节点中的分布,从而实现多副本数据的高可靠和跨机架、跨可用区、跨区域容灾。
当一个 Bookie 节点挂了后,BookKeeper 会自动检测到该节点的失效,并将该节点上的 Ledger 副本切换到其他节点上。具体来说,BookKeeper 会使用 Quorum 机制来进行副本切换,确保新的副本和原有的副本具有相同的数据内容和顺序。在副本切换过程中,BookKeeper 会使用一些机制来保证数据的一致性和完整性,例如写前确认、写后确认等等。
安全控制
传输加密
默认情况下,客户端是通过明文方式与 Broker 通信的,也不需要经过身份认证和授权。为了保证数据在传输过程中的安全,支持通过 TLS 对数据进行加密传输。
使用 netty-tcnative 库在 Broker 中实现支持 TLS。在部署层面,支持在 Broker 和 Proxy 组件开启 TLS。
端到端加密
在生产者端加密消息,然后在消费者端解密消息,从而保证数据在 Broker 保存的是经过加密后的数据,这能有效避免存储在 Broker 中的数据被泄露。
使用动态生成的对称会话密钥来加密数据。
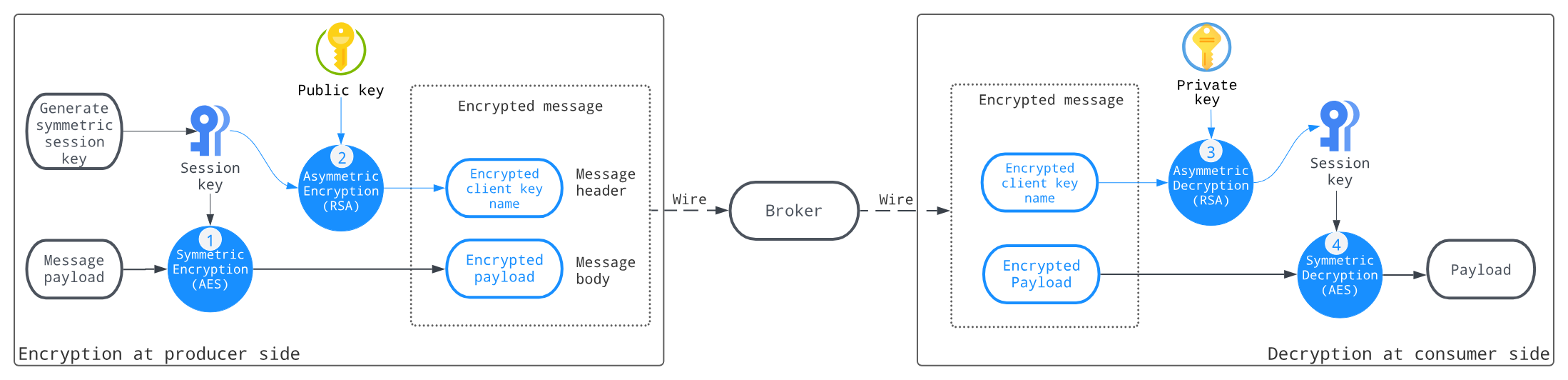
- 生产者会定期(每 4 小时或在发布一定数量的消息后)生成一个会话密钥,然后使用对称算法(例如 AES)对消息进行加密,并每 4 小时获取一次非对称公钥。
- 生产者使用消费者提供的公钥,然后使用非对称算法(例如 RSA)加密会话密钥,并在消息头中携带加密后的会话秘钥信息。
- 消费者读取消息头,并使用其私钥解密会话密钥。
- 消费者使用解密的会话密钥来解密消息。
身份认证
支持 mTLS、JSON Web Token 令牌、Athenz、Kerberos、OAuth 2.0、OpenID Connect、HTTP 基本身份验证等 7 种认证方式。
为了更好地支持多种身份认证方式,在内核提供了一个可插拔的身份认证框架。即通过实现接口,自定义实现身份认证机制。自定义实现插件分为客户端和服务端两部分。
- 自定义实现客户端身份验证插件 org.apache.pulsar.client.api.AuthenticationDataProvider 为 Broker/Proxy 提供身份验
- 自定义实现 Broker/Proxy 身份验证插件 org.apache.pulsar.broker.authentication.AuthenticationProvider 用来对客户端的身份验证数据进行身份验证。
同时支持链式的身份认证,即支持同时配置多种身份认证方式。
资源鉴权
提供插件化的鉴权机制。默认情况下,如果不配置鉴权,认证通过后就可以访问集群中的所有资源。
Broker 当前提供了 AuthorizationProvider 和 MultiRolesTokenAuthorizationProvider 两种鉴权实现,其中 MultiRolesTokenAuthorizationProvider 只支持配合 JWT 认证使用。可以在 Broker 配置文件中配置启用哪种鉴权插件。
通过 Role Token(角色令牌)来完成鉴权。Role Token 本质就是一个字符串,是一个逻辑的概念,用来在后续授权中标识客户端身份用。
从实现上看,认证组件完成认证后会将客户端和角色(Role)关联,即客户端不管使用的是 Auth2.0、JWT 或 Kerberos 认证方式,当通过认证后都会关联一个 Role。然后再根据这个 Role 携带的权限信息来进行鉴权。
Role 分为超级用户和普通用户。超级用户有集群的所有权限,如创建、删除租户,并且对所有租户具有访问权限,超级用户需要在 Broker 的配置文件中进行配置。
另外 Tenant(租户)有 Tenant Admin(租户管理员)概念。在创建租户时,可以指定租户的 Admin Role,这个 Role 拥有这个 Tenant 的全部权限。
支持对 Broker、Tenant、Namespace、Topics 四个维度鉴权。其中 Broker、Tenant 主要是管控级别的操作,比如创建、删除资源等。Namespace 和 Topic 级别的主要是生产和消费相关的权限管控,其中 Namespace 还有 Function 相关的权限控制。
可观测性
指标定义记录
使用 Prometheus 指标库来完成指标记录,通过引入 Java 的 io.prometheus 库实现。在记录指标时,支持 Counter、Gauge、Histogram、Summary 四种指标类型,用来完成瞬时值、统计值、分布值的统计,包含了Broker、BookKeeper、ZooKeeper、Proxy、Function、IO 等等。
指标暴露
通过在组件上支持 HTTP 接口 /metrics 来支持 Prometheus 的采集。接口的数据格式是标准 Prometheus 格式,直接配置 Prometheus 采集 + Grafana 展示或告警即可,使用成本较低。
消息轨迹
当前社区版本不支持,但一些商业化的版本是支持的。
存储计算分离设计
优点
- 对于计算节点不需要存储数据,节点就变成了无状态的(Stateless)节点。一个由无状态节点组成的集群,管理、调度都变得非常简单。集群中每个节点都是一样的,天然就支持水平扩展。任意一个请求都可以路由到集群中任意一个节点上,负载均衡策略可以做得非常灵活,可以随机分配、轮询,也可以根据节点负载动态分配等等。故障转移(Failover)也更加简单快速,如果某个节点故障了,直接把请求分配给其他节点。
- 对比像 ZooKeeper 这样存储计算不分离的系统,故障转移就非常麻烦,一般需要用复杂的选举算法,选出新的 leader,提供服务之前,可能还需要进行数据同步,确保新的节点上的数据和故障节点是完全一致之后,才可以继续提供服务。这个过程是非常复杂而且漫长的。
- 对于计算节点的开发者可以专注于计算业务逻辑开发,而不需要关注像数据一致性、数据可靠性、故障恢复和数据读写性能等等这些比较麻烦的存储问题,极大地降低了开发难度,提升了开发效率。
- 对于存储系统需要实现的功能就很简单,系统的开发者只需要专注于解决“如何安全高效地存储数据?”并且,存储系统的功能是非常稳定的,像 ZooKeeper、HDFS、MySQL 这些存储系统,从它们诞生到现在,功能几乎就没有变过。每次升级都是在优化存储引擎,提升性能、数据可靠性、可用性等等。
缺点
- BookKeeper 依然要解决数据一致性、节点故障转移、选举、数据复制等等这些问题。原来一个集群变成了两个集群,整个系统其实变得更加复杂了。
- 系统的性能也会有一些损失。比如,从 Pulsar 的 Broker 上消费一条消息,Broker 还需要去请求 BookKeeper 集群读取数据,然后返回给客户端,这个过程至少增加了一次网络传输和 n 次内存拷贝。相比于直接读本地磁盘,性能肯定是要差一些的。
事务
消费 + 处理 + 生产的事务。即满足流场景将消费、处理、生产消息整个过程定义为一个原子操作,以保证整个操作的原子性,所以包含的操作有消费、处理、生产三种操作。
![]()
通过事务 ID 来标记事务,开启事务投递消息,都会将消息标记为不可见,同时往一个内部的 Topic 记录事务的状态数据。等全流程处理都成功后,才会提交事务。此时在生产端标记消息可见,在消费端提交消费位点,从而完成整个流程。Pulsar 的事务可以看作是 Kafka 事务的升级版,它保证的是流处理操作的原子性。
Pulsar 存储计算分离的架构是未来消息队列的发展方向?
早期的消息队列,主要被用来在系统之间异步交换数据,大部分消息队列的存储能力都比较弱,不支持消息持久化,不提倡在消息队列中堆积大量的消息,这个时期的消息队列,本质上是一个数据的管道。
现代的消息队列,功能上看似没有太多变化,依然是收发消息,但是用途更加广泛,数据被持久化到磁盘中,大多数消息队列具备了强大的消息堆积能力,只要磁盘空间足够,可以存储无限量的消息,而且不会影响生产和消费的性能。这些消息队列,本质上已经演变成为分布式的存储系统。
为一个“分布式存储系统”做存储计算分离,计算节点就没什么业务逻辑需要计算的了。而且,消息队列又不像其他的业务系统,可以直接使用一些成熟的分布式存储系统来存储消息,因为性能达不到要求。分离后的存储节点承担了之前绝大部分功能,并且增加了系统的复杂度,还降低了性能,显然是不划算的。
现在各大消息队列的 Roadmap(发展路线图),Kafka 在做 Kafka Streams,Pulsar 在做 Pulsar Functions,就是流计算。现有的流计算平台,包括 Storm、Flink 和 Spark,它们的节点都是无状态的纯计算节点,是没有数据存储能力的。所以,现在的流计算平台,它很难做大量数据的聚合,并且在数据可靠性保证、数据一致性、故障恢复等方面,也做得不太好。
而消息队列正好相反,它很好地保证了数据的可靠性、一致性,但是 Broker 只具备存储能力,没有计算的功能,数据流进去什么样,流出来还是什么样。同样是处理实时数据流的系统,一个只能计算不能存储,一个只能存储不能计算,那未来如果出现一个新的系统,既能计算也能存储,如果还能有不错的性能,是不是就会把现在的消息队列和流计算平台都给替代了?这是很有可能的。
对于一个“带计算功能的消息队列”来说,采用存储计算分离的设计,计算节点负责流计算,存储节点负责存储消息,这个设计就非常和谐了。