要点
- Kafka 的每个 Consumer(消费者)实例属于一个 ConsumerGroup(消费组);
- 在消费时,ConsumerGroup 中的每个 Consumer 独占一个或多个 Partition(分区);
- 对于每个 ConsumerGroup,在任意时刻,每个 Partition 至多有 1 个 Consumer 在消费;
- 每个 ConsumerGroup 都有一个 Coordinator(协调者)负责分配 Consumer 和 Partition 的对应关系,当 Partition 或是 Consumer 发生变更时,会触发 reblance(重新分配)过程,重新分配 Consumer 与 Partition 的对应关系;
- Consumer 维护与 Coordinator 之间的心跳,Coordinator 就能感知到Consumer 的状态,在 Consumer 故障的时候及时触发 rebalance。
架构设计与实现
系统架构
由 Producer、Broker、ZooKeeper、Consumer 四个模块组成。其中,ZooKeeper 用来存储元数据信息,集群中所有元数据都持久化存储在 ZooKeeper 当中。
一个 Topic 可以包含一个或多个分区。消费方面通过 Group 来组织消费者和分区的关系。
生产者需要通过客户端寻址拿到元数据信息。客户端通过生产分区分配机制,选择消息发送到哪个分区,然后根据元数据信息拿到分区 Leader 所在的节点,最后将数据发送到 Broker。Broker 收到消息并持久化存储。消费端使用消费分组或直连分区的机制去消费数据,如果使用消费分组,就会经过消费者和分区的分配流程,消费到消息后,最后向服务端提交 Offset 记录消费进度,用来避免重复消费。
协议和网络模块
协议
自定义的私有协议,经过多年发展目前有 V0、V1、V2 三个版本,稳定在 V2 版本。官方没有支持其他的协议,比如 HTTP,但是商业化的 Kafka 一般都会支持 HTTP 协议。
Kafka 协议从结构上来看包含协议头和协议体两部分,协议头包含基础通用的信息,协议体由于每个接口的功能参数不一样,内容结构上差异很大。
网络层
基于 Java NIO 和 Reactor 来开发的,通过多级的线程调度来提高性能。
数据存储
元数据存储
存储在 ZooKeeper 里面的。元数据信息包括 Topic、分区、Broker 节点、配置等信息。ZooKeeper 会持久化存储全量元数据信息,Broker 本身不存储任何集群相关的元数据信息。在 Broker 启动的时候,需要连接 ZooKeeper 读取全量元数据信息。
另外,Kakfa 集群中的一些如消费进度信息、事务信息,分层存储元数据,以及 3.0 后的 Raft 架构相关的元数据信息,都是基于内置 Topic 来完成存储的。
消息数据
以分区为维度单独存储的。即写入数据到 Topic 后,根据生产分区分配关系,会将数据分发到 Topic 中不同的分区。此时底层不同分区的数据是存储在不同的“文件”中的,即一个分区一个数据存储“文件”。这里提到的“文件”也是一个虚指,在系统底层的表现是一个目录,里面的文件会分段存储。
当 Broker 收到数据后,是直接将数据写入到不同的分区文件中的。所以在消费的时候,消费者也是直接从每个分区读取数据。
在底层数据存储中,Kafka 的存储结构是以 Topic 和分区维度来组织的。一个分区一个目录,目录名称是 TopicName + 分区号。
1
2
3
4
5
6
7
/data/kafka/data#ll
drwxr-xr-x 2 root root 4096 2月 15 2020 __consumer_offsets-0
drwxr-xr-x 2 root root 4096 2月 15 2020 __consumer_offsets-1
drwxr-xr-x 2 root root 4096 2月 15 2020 __consumer_offsets-2
drwxr-xr-x 2 root root 4096 2月 15 2020 __transaction_state-0
drwxr-xr-x 2 root root 4096 2月 15 2020 __transaction_state-1
drwxr-xr-x 2 root root 4096 2月 15 2020 __transaction_state-2
每个分区的目录下,有三类文件。
- .log 是消息数据的存储文件
- .index 是偏移量(offset)索引文件
- .timeindex 是时间戳索引文件。两个索引文件分别根据 Offset 和时间来检索数据。
每个索引中保存索引序号(也就是这条消息是这个分区中的第几条消息)和对应的消息在消息文件中的绝对位置。在索引的设计上,Kafka 采用的是稀疏索引,为了节省存储空间,它不会为每一条消息都创建索引,而是每隔几条消息创建一条索引。
写入消息的就是在消息文件尾部连续追加写入,一个文件写满了再写下一个文件。由于每个分区存储的数据量会很大,分区数据也会进行分段存储。分段是在.log 进行的,文件分段的默认数据大小也是 1G,可以通过配置项来修改。
查找消息时,首先根据文件名找到所在的索引文件,然后用二分法遍历索引文件内的索引,在里面找到离目标消息最近的索引,再去消息文件中,找到这条最近的索引指向的消息位置,从这个位置开始顺序遍历消息文件,找到目标消息。寻址过程是需要一定时间的。一旦找到消息位置后,就可以批量顺序读取,不必每条消息都要进行一次寻址。
在节点维度,也会持久存储当前节点的数据信息(如 BrokerID)和一些异常恢复用的 Checkpoint 等数据。
提供了根据过期时间和数据大小清理的机制,清理机制是在 Topic 维度生效的。当数据超过配置的过期时间或者超过大小的限制之后,就会进行清理。通过延时清理的机制,根据每个段文件进行清理的,即整个文件的数据都过期后,才会清理数据。
根据大小清理的机制是在分区维度生效的,不是 Topic。即当分区的数据大小超过设置的大小,就会触发清理逻辑。
在存储性能上,Kafka 的写入大量依赖顺序写、写缓存、批量写来提高性能。消费方面依赖批量读、顺序读、读缓存的热数据、零拷贝来提高性能。
生产者和消费者
客户端在连接 Broker 之前需要经过客户端寻址,找到目标 Broker 的信息。在早期,客户端是通过链接 ZooKeeper 完成寻址操作的,但是因为 ZooKeeper 的性能不够,如果大量的客户端都访问 ZooKeeper,那么就会导致 ZooKeeper 超载,从而导致集群异常。
在新版本中,客户端是通过直连 Broker 完成寻址操作的,不会跟 ZooKeeper 交互。即 Broker 跟 ZooKeeper 交互,在本地缓存全量的元数据信息,然后客户端通过连接 Broker 拿到元数据信息,从而避免对 ZooKeeper 造成太大负载。
生产者
生产者完成寻址后,在发送的时候可以将数据发送到 Topic 或者直接发送到分区。发送到 Topic 时会经过生产分区分配的流程,即根据一定的策略将数据发送到不同的分区。
- 轮询策略:按消息维度轮询,将数据平均分配到多个分区。
- Key Hash:根据消息的 Key 生成一个 Hash 值,然后和分区数量进行取余操作,得到的结果可以确定要将数据发送到哪个分区。生产消息分配的过程是在客户端完成的。
Kafka 协议提供了批量(Batch)发送的语义。所以生产端会在本地先缓存数据,根据不同的分区聚合数据后,再根据一定的策略批量将数据写入到 Broker,从而提高客户端和服务端的吞吐性能。
客户端批量往服务端写有两种形式:
- 协议和内核就提供了 Batch 语义
- 在业务层将一批数据聚合成一次数据发送。
这两种虽然都是批量发送,但是它们的区别在于:
- 第一种批量消息中的每条消息都会有一个 Offset,每条消息在 Broker 看来就是一条消息。第二种批量消息是这批消息就是一条消息,只有一个 Offset。
- 在消费端看来,第一种对客户端是无感的,一条消息就是一条消息。第二种需要消费者感知生产的批量消息,然后解析批量,逐条处理。
消费端
只提供了 Pull(拉)模式的消费。即客户端是主动不断地去服务端轮询数据、获取数据,消费则是直接从分区拉取数据的。提供了消费分组消费和直连分区消费两种模式,这两者的区别在于,是否需要进行消费者和分区的分配,以及消费进度谁来保存。
大部分情况下,都是基于消费分组消费。消费分组创建、消费者或分区变动的时候会进行重平衡,重新分配消费关系。默认提供了 RangeAssignor(范围)、RoundRobinAssignor(轮询)、 StickyAssignor(粘性)三种策略,也可以自定义策略。
消费分组模式下,一个分区只能给一个消费者消费,消费是顺序的。当客户端成功消费数据后,会往服务端提交消费进度信息,此时服务端也不会删除具体的消息数据,只会保存消费位点信息。位点数据保存在内部的一个 Topic(__consumer_offset)中。消费端提供了自动提交和手动提交两种模式。当消费者重新启动时,会根据上一次保存的位点去消费数据,用来避免重复消费。
HTTP 协议支持和管控操作
内核是不支持 HTTP 协议的,如果需要支持,则需要在 Broker 前面挂一层代理。
管控的大部分操作是通过 Kafka Protocol 暴露的,基于四层的 TCP 进行通信。还有部分可以通过直连 ZooKeeper 完成管控操作。
在早期很多管控操作都是通过操作 ZooKeeper 完成的。后来为了避免对 ZooKeeper 造成压力,所有的管控操作都会通过 Broker 再封装一次,即客户端 SDK 通过 Kafka Protocol 调用 Broker,Broker 再去和 ZooKeeper 交互。
命令行提供了管控、生产、消费、压测等功能,其底层就是通过客户端 SDK 和 Broker 进行交互的。
因为历史的演进,在一些命令行里面,还残留着直连 ZooKeeper 的操作。可通过直接操作 ZooKeeper 中的数据完成一些操作,比如更改配置、创建 Topic 等等。
集群构建
基于 ZooKeeper 的集群
将 ZooKeeper 作为节点发现和元数据存储的组件,通过在 ZooKeeper 上创建临时节点来完成节点发现,并在不同的节点上保存各种元数据信息。
Broker 在启动或重连时,会根据配置中的 ZooKeeper 地址找到集群对应的 ZooKeeper 集群。然后会在 ZooKeeper 的 /broker/ids 目录中创建名称为自身 BrokerID 的临时节点,同时在节点中保存自身的 Broker IP 和 ID 等信息。当 Broker 宕机或异常时,TCP 连接就会断开或者超时,此时临时节点就会被删除。节点之间的探活依赖 ZooKeeper 内置的探活机制。
Controller 是一个虚拟概念,是运行在某台 Broker 上的一段代码逻辑。集群中需要确认一台 Broker 承担 Controller 的角色,每台 Broker 启动的时候都会去 ZooKeeper 判断一下这个节点是否存在。如果存在就认为已经有 Controller 了,如果没有,就把自己的信息注册上去,自己来当 Controller。集群每个 Broker 都会监听 /Controller 节点,当监听到节点不存在时,都会主动去尝试创建节点,注册自己的信息。哪台节点注册成功,这个节点就是新的 Controller。
Controller 会监听 ZooKeeper 上多个不同目录,主要监听目录中子节点的增加、删除,节点内容变更等行为。集群中每台 Broker 中都有集群全量的元数据信息,每台节点的元数据信息大部分是通过 Controller 来维护的。
创建 Topic 有两种形式,即通过 Broker 来创建和通过 ZooKeeper 来创建。当调用 Broker 创建 Topic 时,Broker 会根据本地的全量元数据信息,算出新 Topic 的分区、副本分布,然后将这些数据写入到 ZooKeeper。然后 Controller 就会 Hook 到创建 Topic 的行为,更新本地缓存元数据信息,通知对应的 Broker 节点创建分区和副本。 所以,也可以通过直接生成计划然后写入到 ZooKeeper 的方式来创建 Topic。
基于 KRaft 的集群
将集群的元数据存储服务从 ZooKeeper 替换成为内部实现的 Metadata 模块。这个模块会同时完成 Controller和元数据存储的工作。
集群元数据需要分布式存储才能保证数据的高可靠,KRaft 架构的 Metadata 模块是基于 Raft 协议实现的 KRaft,从而实现元数据可靠存储的。
Metadata 模块只需要完成元数据存储,和 ZooKeeper 是主从架构。即通过在配置文件中配置节点列表,然后通过投票来选举出 Leader 节点。这个节点会承担集群管控、元数据存储和分发等功能。
Metadata 模块通过配置项 controoler.quorum.votes 配置允许成为 Controller 的节点列表,然后这些节点之间会通过投票选举出 Leader 节点,这个 Leader 会完成 Controller 和元数据存储的工作。
Broker 之间通过投票选举出来的 Leader 节点就是 Controller。此时所有 Broker 都会和 Controller 保持通信,以维护节点的在线状态,从而完成节点发现。当 Controller 发现 Broker 增加或异常时,就会主动执行后续的操作。
从链路来看,这个架构简化了通过监听 ZooKeeper 来发现节点变更的流程,链路更短,稳定性更高。和基于 ZooKeeper 的架构一样,每台 Broker 依旧有集群全量的元数据信息,这些元数据信息的维护也是通过 Controller 完成的。
创建 Topic 只有通过 Broker 创建的方式。通过 Admin SDK 调用 Broker 创建 Topic,如果 Broker 不是 Controller,这个请求就会转发到当前的 Controller 上。Controller 会根据本地的元数据信息生成新 Topic 的分区、副本的分布,然后调用对应的 Broker 节点完成分区和副本数据的创建,最后会保存元数据。
数据可靠性
集群维度的数据可靠性也是通过副本来实现的,而副本间数据一致性是通过 ISR 协议来保证的。ISR 协议是现有一致性协议的变种,它是参考业界主流的一致性协议,设计出来的符合流消息场景的一致性协议。
ISR 协议的核心思想是:通过副本拉取 Leader 数据、动态维护可用副本集合、控制 Leader 切换和数据截断 3 个方面,来提高性能和可用性。
这种机制在流消息队列的大吞吐场景中主要有两个缺点:
- 收到数据立即分发给多个副本,在请求量很大时,和副本之间的频繁交互会导致数据分发的性能不高。
- 计算一致性的总副本数是固定的,当某个副本异常时,如果还往这个副本分发数据,此时会影响集群性能。
副本拉取 Leader 数据
通过 Follower 批量从 Leader 拉取数据来完成主从副本间的数据同步,并提高性能的。
当配置最终一致(ACK=1)或者强一致(ACK=-1)时,Leader 接收到数据后不会立即告诉客户端写入成功。而是请求会进入一个本地的队列进行等待,等待 Follower 完成数据同步。当数据被副本同步后,Leader 才会告诉客户端写入成功。
等待这个行为的技术实现的核心思想是 Leader 维护的定时器,时间轮。简单理解就是时间轮会定时检查数据是否被同步,是的话就返回成功,否的话就判断是否超时,超时就返回超时错误,否则就继续等待。
动态维护可用副本集合
ISR 会维护一个可用的副本集合。
副本异常判断:
- 节点的心跳的探活机制,判断副本所在节点是否宕机
- 副本的数据拉取进度是否跟不上 Leader,即副本来 Leader Pull 数据的速度跟不上数据写入 Leader 数据的速度。支持按数据条数或时间去判断 Follower 是否跟得上 Leader。
控制 Leader 切换和数据截断
ISR 协议是最终一致的,所以在某些极端的场景中会出现数据丢失和截断,所以需要在实现上做特殊的处理。
- 问题发生时,服务就不可用。
- 丢弃数据
安全控制
传输加密
支持 TLS/SSL 进行数据加密传输。
认证
在身份验证和安全SASL的框架下实现了GSSAPI、PLAIN、SCRAM、OAUTHBEARER、Delegation Token 5 种认证方式。
- GSSAPI 全称是通用安全服务应用编程接口(Generic Security Service Application Programming Interface, GSS-API)的简称,它的目的是为应用程序提供一种用于保护发送数据的方法。它主要用在和 Kerberos(安全的、单点登录的、可信的第三方相互身份验证服务)认证对接的过程。
- PLAIN:明文的用户名、密码认证机制,通过服务端提供的用户名密码来完成校验。
- SCRAM:明文的认证机制。它跟 PLAIN 最大的区别是,它的用户名和密码是存储在 ZooKeeper 中的,并支持动态修改。
- OAUTHBEARER:支持 OAuth 认证机制而引入。
- Delegation Token:一种轻量级的 Token 认证机制,从实现原理来看,就是服务端签发保存 Token,客户端携带 Token 来完成认证。Token 信息也是保存在 ZooKeeper 上的。
鉴权
对资源的管控粒度主要支持对 Topic、Group、Cluster、TransactionalId、DelegationToken、User 等 6 种资源进行控制,并给这些资源提供了Read、Write、Create、Delete、Alter、Describe、ClusterAction、DescribeConfigs、AlterConfigs、IdempotentWrite、CreateTokens、DescribeTokens、All 等 13 种权限,分别对应数据的读写、资源的增删改查、集群管控、配置修改、Token 配置、全部权限等类型。也支持对来源 IP 的限制。
在 Broker 启动时,会加载全部权限信息到内存中。当客户端访问某个功能时,会率先进行权限比对。当 ZooKeeper 节点的内容更新时,会下发通知,通知 Broker 重新读取 ZooKeeper 节点中的数据更新内存的内容。
可观测性
指标
基于 Yammer Metrics 库来实现的。Yammer Metrics 是 Java 中一个常用的指标库,它提供了 Histogram、Meters、Gauges 等类型来统计数据。
在指标暴露方面,Kakfa 只支持 JMX 方式的指标获取。即如果需要从 Kafka 进程采集指标,就需要先在 Broker 上开启 JMX Server。然后客户端通过 JMX Client 去 Broker 采集对应的
在实际运营中,主要有 3 种通过指标监控 Broker 的方式。
- 通过代码使用 JMX Client 直接去采集 Broker 中的指标数据,然后自定义处理。
- 通过 JMX Export 采集指标,然后和 Prometheus 集成展示。从实现来看,JMX Export 底层也是通过 JMX Client 去 Broker 采集数据的。
- 社区提供了 Kafka Export 通过 Kafka Protocol 去获取消费进度、Topic 信息等相关信息,然后再和 Prometheus 集成展示。
日志
基于 Log4j 库去打印日志,依赖 Log4j 库的强大,支持常见的日志功能。
同时通过配置支持,将不同模块的日志打印到不同文件,如 Controller、Coordinator、GC 等等,以便在运营过程中提高问题排查的效率。
消息轨迹
没有提供对消息轨迹功能的支持。
主要是因为定位的是流场景、大吞吐的消息队列。一般用在日志场景中,这些场景消息数量是非常大的。如果支持消息轨迹,那么一条消息至少需要生产者、Broker、消费者 3 条轨迹信息,此时轨迹数据的量就非常恐怖,从成本角度来看收益很低。
消息复制
复制的基本单位是分区。每个分区的几个副本之间,构成一个小的复制集群,Broker 只是这些分区副本的容器,所以 Broker 是不分主从的。
分区的多个副本中采用一主多从的方式。Kafka 在写入消息的时候,采用的也是异步复制的方式。消息在写入到主节点之后,并不会马上返回写入成功,而是等待足够多(用户自己决定)的节点都复制成功后再返回。
使用 ZooKeeper 来监控每个分区的多个节点,如果发现某个分区的主节点宕机了,会利用 ZooKeeper 来选出一个新的主节点。
事务
用于实现它的 Exactly Once 机制,应用于实时计算的场景中。
确保在一个事务中发送的多条消息,要么都成功,要么都失败。注意,这里面的多条消息不一定要在同一个主题和分区中,可以是发往多个主题和分区的消息。
单独来使用的场景不多,更多的情况下被用来配合 Kafka 的幂等机制来实现 Kafka 的 Exactly Once 语义。
角色
事务协调者:负责在服务端协调整个事务。这个协调者并不是一个独立的进程,而是 Broker 进程的一部分,协调者和分区一样通过选举来保证自身的可用性。
Kafka 集群中有一个特殊的用于记录事务日志的主题,这个事务日志主题的实现和普通的主题是一样的,里面记录的数据就是类似于“开启事务”“提交事务”这样的事务日志。日志主题同样也包含了很多的分区。在 Kafka 集群中,可以存在多个协调者,每个协调者负责管理和使用事务日志中的几个分区,并行执行多个事务,提升性能。
![]()
实现流程
- 开启事务,生产者会给协调者发一个请求来开启事务,协调者在事务日志中记录下事务 ID。
- 生产者在发送消息之前,还要给协调者发送请求,告知发送的消息属于哪个主题和分区,这个信息也会被协调者记录在事务日志中。
- 生产者像发送普通消息一样来发送事务消息,直接发给 Broker,保存在这些消息对应的分区中,Kafka 会在客户端的消费者中,暂时过滤未提交的事务消息。
- 消息发送完成后,生产者给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务。第一阶段,协调者把事务的状态设置为“预提交”,并写入事务日志。实际上事务已经成功了,无论接下来发生什么情况,事务最终都会被提交。
- 第二阶段,协调者在事务相关的所有分区中,都会写一条“事务结束”的特殊消息,当 Kafka 的消费者读到这个事务结束的特殊消息之后,它就可以把之前暂时过滤的那些未提交的事务消息,放行给业务代码进行消费了。
- 协调者记录最后一条事务日志,标识这个事务已经结束了。
Flink
保证 Exactly Once 语义
端到端 Exactly Once 指的是,数据从 Kafka 的 A 主题消费,发送给 Flink 的计算集群进行计算,计算结果再发给 Kafka 的 B 主题。在这整个过程中,无论是 Kafka 集群的节点还是 Flink 集群的节点发生故障,都不会影响计算结果,每条消息只会被计算一次,不能多也不能少。
Flink 通过 CheckPoint 机制来定期保存计算任务的快照,这个快照中主要包含两个重要的数据:
- 整个计算任务的状态。这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据。
- 数据源的位置信息。这个信息记录了在数据源的这个流中已经计算了哪些数据。如果数据源是 Kafka 的主题,这个位置信息就是 Kafka 主题中的消费位置。
当计算任务失败重启的时候,每个子任务先从 CheckPoint 中读取并恢复自己的状态,然后整个计算任务从 CheckPoint 中记录的数据源位置开始消费数据,只要这个恢复位置和 CheckPoint 中每个子任务的状态是完全对应的,或者说,每个子任务的状态恰好是:“刚刚处理完恢复位置之前的那条数据,还没有开始处理恢复位置对应的这条数据”,这个时刻保存的状态,就可以做到严丝合缝地恢复计算任务,每一条数据既不会丢失也不会重复。
Flink 通过在数据流中插入一个 Barrier(屏障)来确保 CheckPoint 中的位置和状态完全对应。

Barrier 为一条特殊的数据,由 Flink 生成,并在数据进入计算集群时被插入到数据流中。无限的数据流就被很多的 Barrier 分隔成很多段。Barrier 在流经每个计算节点的时候,就会触发这个节点在 CheckPoint 中保存本节点的状态,如果这个节点是数据源节点,还会保存数据源的位置。
当一个 Barrier 流过所有计算节点,流出计算集群后,一个 CheckPoint 也就保存完成了。由于每个节点都是在 Barrier 流过的时候保存的状态,这时的状态恰好就是 Barrier 所在位置(也就是 CheckPoint 数据源位置)对应的状态,这样就完美解决了状态与恢复位置对应的问题。
Flink 通过 CheckPoint 机制实现了集群内计算任务的 Exactly Once 语义,但是仍然实现不了在输入和输出两端数据不丢不重。比如,Flink 在把一条计算结果发给 Kafka 并收到来自 Kafka 的“发送成功”响应之后,才会继续处理下一条数据。如果这个时候重启计算任务,Flink 集群内的数据都可以完美地恢复到上一个 CheckPoint,但是已经发给 Kafka 的消息却没办法撤回,还是会出现数据重复的问题。
配合实现端到端 Exactly Once
Kafka 的 Exactly Once 语义是通过它的事务和生产幂等两个特性来共同实现的。它可以保证一个事务内的所有消息,要么都成功投递,要么都不投递。
生产幂等:通过连续递增的序号进行检测。Kafka 的生产者给每个消息增加都附加一个连续递增的序号,Broker 端会检测这个序号的连续性,如果序号重复了,Broker 会拒绝这个重复消息。
每个 Flink 的 CheckPoint 对应一个 Kafka 事务。Flink 在创建一个 CheckPoint 的时候,同时开启一个 Kafka 的事务,完成 CheckPoint 同时提交 Kafka 的事务。当计算任务重启的时候,在 Flink 中计算任务会恢复到上一个 CheckPoint,这个 CheckPoint 正好对应 Kafka 上一个成功提交的事务。未完成的 CheckPoint 和未提交的事务中的消息都会被丢弃,这样就实现了端到端的 Exactly Once。
Flink 基于两阶段提交这个常用的分布式事务算法,实现了一分布式事务的控制器保证“完成 CheckPoint 同时提交 Kafka 的事务”来解决这个问题。
选举
Kafka 分区的 Leader并不是选举出来的,而是 Controller 指定的。Kafka 使用 ZooKeeper 来监控每个分区的多个副本,如果发现某个分区的主节点宕机了,Controller 会收到 ZooKeeper 的通知,从 ISR 节点中选择一个节点,指定为新的 Leader。
在 Kafka 中 Controller 本身也是通过 ZooKeeper 选举产生的。严格来说是一种抢占模式。每个Broker 在启动后,都会尝试在 ZooKeeper 中创建同一个临时节点:/controller,并把自身的信息写入到这个节点中。由于 ZooKeeper 它是一个可以保证数据一致性的分布式存储,所以,集群中只会有一个 Broker 抢到这个临时节点,那它就是 Leader 节点。其他没抢到 Leader 的节点,会 Watch 这个临时节点,如果当前的 Leader 节点宕机,所有其他节点都会收到通知,它们会开始新一轮的抢 Leader。
源码分析
Consumer
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// clients/src/main/java/org/apache/kafka/clients/consumer/KafkaConsumer.java
// 设置必要的配置信息
// 包括:起始连接的 Broker 地址,Consumer Group 的 ID,自动提交消费位置的配置和序列化配置;
Properties props = new Properties();
props.setProperty(bootstrap.servers, localhost:9092);
props.setProperty(group.id, test);
props.setProperty(enable.auto.commit, true);
props.setProperty(auto.commit.interval.ms, 1000);
props.setProperty(key.deserializer, org.apache.kafka.common.serialization.StringDeserializer);
props.setProperty(value.deserializer, org.apache.kafka.common.serialization.StringDeserializer);
// 创建 Consumer 实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅了 2 个 Topic:foo 和 bar;
consumer.subscribe(Arrays.asList(foo, bar));
// 循环拉消息,并打印在控制台上
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf(offset = %d, key = %s, value = %s%n, record.offset(), record.key(), record.value());
}
订阅过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
/**
* Internal helper method for {@link #subscribe(Collection)} and
* {@link #subscribe(Collection, ConsumerRebalanceListener)}
* <p>
* Subscribe to the given list of topics to get dynamically assigned partitions.
* <b>Topic subscriptions are not incremental. This list will replace the current
* assignment (if there is one).</b> It is not possible to combine topic subscription with group management
* with manual partition assignment through {@link #assign(Collection)}.
*
* If the given list of topics is empty, it is treated the same as {@link #unsubscribe()}.
*
* <p>
* @param topics The list of topics to subscribe to
* @param listener {@link Optional} listener instance to get notifications on partition assignment/revocation
* for the subscribed topics
* @throws IllegalArgumentException If topics is null or contains null or empty elements
* @throws IllegalStateException If {@code subscribe()} is called previously with pattern, or assign is called
* previously (without a subsequent call to {@link #unsubscribe()}), or if not
* configured at-least one partition assignment strategy
*/
private void subscribeInternal(Collection<String> topics, Optional<ConsumerRebalanceListener> listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
for (String topic : topics) {
if (isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
throwIfNoAssignorsConfigured();
// Clear the buffered data which are not a part of newly assigned topics
final Set<TopicPartition> currentTopicPartitions = new HashSet<>();
for (TopicPartition tp : subscriptions.assignedPartitions()) {
if (topics.contains(tp.topic()))
currentTopicPartitions.add(tp);
}
fetcher.clearBufferedDataForUnassignedPartitions(currentTopicPartitions);
log.info("Subscribed to topic(s): {}", String.join(", ", topics));
// 重置订阅状态
// 主要维护了订阅的 topic 和 patition 的消费位置等状态信息
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
// 更新元数据
// 属性 metadata 中维护了 Kafka 集群元数据的一个子集,包括集群的 Broker 节点、Topic 和 Partition 在节点上分布
// 以及Coordinator 给 Consumer 分配的 Partition 信息。
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}
/**
* Request an immediate update of the current cluster metadata info, because the caller is interested in
* metadata that is being newly requested.
* @return The current updateVersion before the update
*/
// 必须确保在第一次拉消息之前元数据是可用的,也就是说在第一次拉消息之前必须更新一次元数据,否则 Consumer 就不知道它应该去哪个 Broker 上去拉哪个 Partition 的消息。
public synchronized int requestUpdateForNewTopics() {
// Override the timestamp of last refresh to let immediate update.
this.lastRefreshMs = 0;
this.needPartialUpdate = true;
this.equivalentResponseCount = 0;
this.requestVersion++;
return this.updateVersion;
}
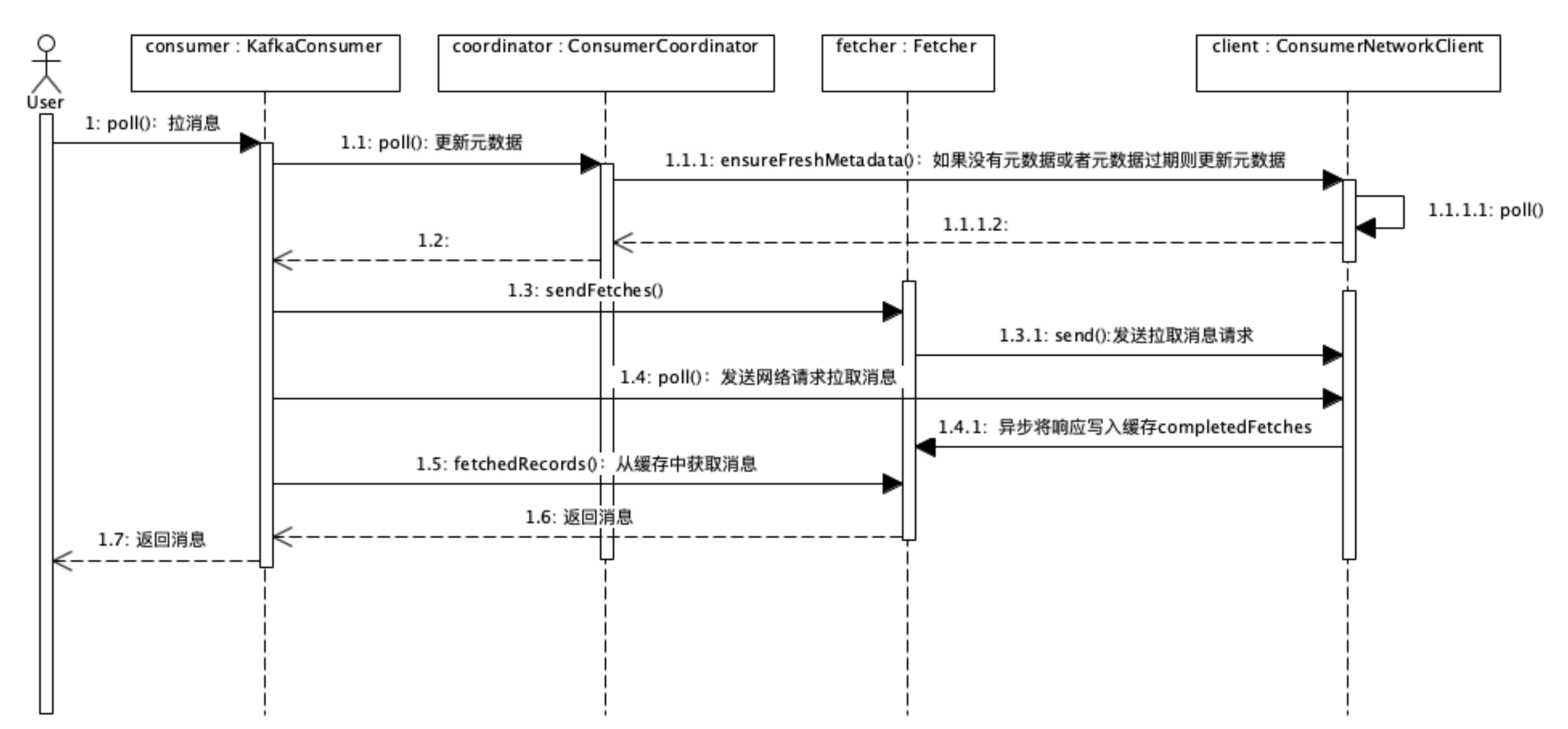
拉取消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
// clients/src/main/java/org/apache/kafka/clients/consumer/internals/ClassicKafkaConsumer.java
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private ConsumerRecords<K, V> poll(final Timer timer) {
acquireAndEnsureOpen();
try {
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
// try to update assignment metadata BUT do not need to block on the timer for join group
// 更新元数据,最终现了与 Cluster 通信,在 Coordinator 上注册 Consumer 并拉取和更新元数据。
// 类 ConsumerNetworkClient 封装了 Consumer 和 Cluster 之间所有的网络通信的实现,这个类是一个非常彻底的异步实现。
// 它没有维护任何的线程,所有待发送的 Request 都存放在属性 unsent 中,返回的 Response 存放在属性 pendingCompletion 中。
// 每次调用poll() 方法的时候,在当前线程中发送所有待发送的 Request,处理所有收到的Response。
updateAssignmentMetadataIfNeeded(timer, false);
// 拉取消息
final Fetch<K, V> fetch = pollForFetches(timer);
if (!fetch.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
if (fetch.records().isEmpty()) {
log.trace("Returning empty records from `poll()` "
+ "since the consumer's position has advanced for at least one topic partition");
}
return this.interceptors.onConsume(new ConsumerRecords<>(fetch.records(), fetch.nextOffsets()));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private Fetch<K, V> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// if data is available already, return it immediately
// 如果缓存里面有未读取的消息,直接返回这些消息
final Fetch<K, V> fetch = fetcher.collectFetch();
if (!fetch.isEmpty()) {
return fetch;
}
// send any new fetches (won't resend pending fetches)
// 构造拉取消息请求,并发送
// Kafka 根据元数据的信息,构造到所有需要的Broker 的拉消息的 Request,然后调用 client.Send() 方法将这些请求异步发送出去。
// 并且,注册了一个回调类来处理返回的 Response,所有返回的 Response 被暂时存放在Fetcher.completedFetches 中。
// 需要注意的是,这时的 Request 并没有被真正发给各个Broker,而是被暂存在了 client.unsend 中等待被发送。
sendFetches();
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHasAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHasAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = time.timer(pollTimeout);
// 发送网络请求拉取消息,等待直到有消息返回或者超时
// 真正将之前构造的所有 Request 发送出去,并处理收到的 Response。
client.poll(pollTimer, () -> {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// 返回拉到的消息
// 返回的 Response 反序列化后转换为消息列表,返回给调用者。
return fetcher.collectFetch();
}
协调服务ZooKeeper
客户端寻找Broker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
// clients/src/main/java/org/apache/kafka/clients/NetworkClient.java
/**
* Add a metadata request to the list of sends if we can make one
*/
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
if (canSendRequest(nodeConnectionId, now)) {
// 构建一个更新元数据的请求的构造器
// 在这个方法里面创建的并不是一个真正的更新元数据的 MetadataRequest,而是一个用于构造 MetadataRequest 的构造器 MetadataRequest.Builder,
// 等到真正要发送请求之前,Kafka 才会调用 Builder.buid() 方法把这个 MetadataRequest 构建出来然后发送出去。
// 而且,不仅是元数据的请求,所有的请求都是这样来处理的。
Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);
MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;
log.debug("Sending metadata request {} to node {}", metadataRequest, node);
// 发送更新元数据的请求
// 这个请求也并没有被真正发出去,依然是保存在待发送的队列中,然后择机来异步批量发送。
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);
return defaultRequestTimeoutMs;
}
// If there's any connection establishment underway, wait until it completes. This prevents
// the client from unnecessarily connecting to additional nodes while a previous connection
// attempt has not been completed.
if (isAnyNodeConnecting()) {
// Strictly the timeout we should return here is "connect timeout", but as we don't
// have such application level configuration, using reconnect backoff instead.
return reconnectBackoffMs;
}
if (connectionStates.canConnect(nodeConnectionId, now)) {
// We don't have a connection to this node right now, make one
log.debug("Initialize connection to node {} for sending metadata request", node);
initiateConnect(node, now);
return reconnectBackoffMs;
}
// connected, but can't send more OR connecting
// In either case, we just need to wait for a network event to let us know the selected
// connection might be usable again.
return Long.MAX_VALUE;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
// core/src/main/scala/kafka/server/KafkaApis.scala
def handleTopicMetadataRequest(request: RequestChannel.Request): Unit = {
val metadataRequest = request.body[MetadataRequest]
val requestVersion = request.header.apiVersion
// Topic IDs are not supported for versions 10 and 11. Topic names can not be null in these versions.
if (!metadataRequest.isAllTopics) {
metadataRequest.data.topics.forEach{ topic =>
if (topic.name == null && metadataRequest.version < 12) {
throw new InvalidRequestException(s"Topic name can not be null for version ${metadataRequest.version}")
} else if (topic.topicId != Uuid.ZERO_UUID && metadataRequest.version < 12) {
throw new InvalidRequestException(s"Topic IDs are not supported in requests for version ${metadataRequest.version}")
}
}
}
// Check if topicId is presented firstly.
val topicIds = metadataRequest.topicIds.asScala.toSet.filterNot(_ == Uuid.ZERO_UUID)
val useTopicId = topicIds.nonEmpty
// Only get topicIds and topicNames when supporting topicId
val unknownTopicIds = topicIds.filter(metadataCache.getTopicName(_).isEmpty)
val knownTopicNames = topicIds.flatMap(metadataCache.getTopicName)
val unknownTopicIdsTopicMetadata = unknownTopicIds.map(topicId =>
metadataResponseTopic(Errors.UNKNOWN_TOPIC_ID, null, topicId, isInternal = false, util.Collections.emptyList())).toSeq
// 计算需要获取哪些主题的元数据
val topics = if (metadataRequest.isAllTopics)
metadataCache.getAllTopics()
else if (useTopicId)
knownTopicNames
else
metadataRequest.topics.asScala.toSet
val authorizedForDescribeTopics = authHelper.filterByAuthorized(request.context, DESCRIBE, TOPIC,
topics, logIfDenied = !metadataRequest.isAllTopics)(identity)
var (authorizedTopics, unauthorizedForDescribeTopics) = topics.partition(authorizedForDescribeTopics.contains)
var unauthorizedForCreateTopics = Set[String]()
if (authorizedTopics.nonEmpty) {
val nonExistingTopics = authorizedTopics.filterNot(metadataCache.contains)
if (metadataRequest.allowAutoTopicCreation && config.autoCreateTopicsEnable && nonExistingTopics.nonEmpty) {
if (!authHelper.authorize(request.context, CREATE, CLUSTER, CLUSTER_NAME, logIfDenied = false)) {
val authorizedForCreateTopics = authHelper.filterByAuthorized(request.context, CREATE, TOPIC,
nonExistingTopics)(identity)
unauthorizedForCreateTopics = nonExistingTopics.diff(authorizedForCreateTopics)
authorizedTopics = authorizedTopics.diff(unauthorizedForCreateTopics)
}
}
}
val unauthorizedForCreateTopicMetadata = unauthorizedForCreateTopics.map(topic =>
// Set topicId to zero since we will never create topic which topicId
metadataResponseTopic(Errors.TOPIC_AUTHORIZATION_FAILED, topic, Uuid.ZERO_UUID, isInternal(topic), util.Collections.emptyList()))
// do not disclose the existence of topics unauthorized for Describe, so we've not even checked if they exist or not
val unauthorizedForDescribeTopicMetadata =
// In case of all topics, don't include topics unauthorized for Describe
if ((requestVersion == 0 && (metadataRequest.topics == null || metadataRequest.topics.isEmpty)) || metadataRequest.isAllTopics)
Set.empty[MetadataResponseTopic]
else if (useTopicId) {
// Topic IDs are not considered sensitive information, so returning TOPIC_AUTHORIZATION_FAILED is OK
unauthorizedForDescribeTopics.map(topic =>
metadataResponseTopic(Errors.TOPIC_AUTHORIZATION_FAILED, null, metadataCache.getTopicId(topic), isInternal = false, util.Collections.emptyList()))
} else {
// We should not return topicId when on unauthorized error, so we return zero uuid.
unauthorizedForDescribeTopics.map(topic =>
metadataResponseTopic(Errors.TOPIC_AUTHORIZATION_FAILED, topic, Uuid.ZERO_UUID, isInternal = false, util.Collections.emptyList()))
}
// In version 0, we returned an error when brokers with replicas were unavailable,
// while in higher versions we simply don't include the broker in the returned broker list
val errorUnavailableEndpoints = requestVersion == 0
// In versions 5 and below, we returned LEADER_NOT_AVAILABLE if a matching listener was not found on the leader.
// From version 6 onwards, we return LISTENER_NOT_FOUND to enable diagnosis of configuration errors.
val errorUnavailableListeners = requestVersion >= 6
val allowAutoCreation = config.autoCreateTopicsEnable && metadataRequest.allowAutoTopicCreation && !metadataRequest.isAllTopics
// 从元数据缓存过滤出相关主题的元数据
val topicMetadata = getTopicMetadata(request, metadataRequest.isAllTopics, allowAutoCreation, authorizedTopics,
request.context.listenerName, errorUnavailableEndpoints, errorUnavailableListeners)
var clusterAuthorizedOperations = Int.MinValue // Default value in the schema
if (requestVersion >= 8) {
// get cluster authorized operations
if (requestVersion <= 10) {
if (metadataRequest.data.includeClusterAuthorizedOperations) {
if (authHelper.authorize(request.context, DESCRIBE, CLUSTER, CLUSTER_NAME))
clusterAuthorizedOperations = authHelper.authorizedOperations(request, Resource.CLUSTER)
else
clusterAuthorizedOperations = 0
}
}
// get topic authorized operations
if (metadataRequest.data.includeTopicAuthorizedOperations) {
def setTopicAuthorizedOperations(topicMetadata: Seq[MetadataResponseTopic]): Unit = {
topicMetadata.foreach { topicData =>
topicData.setTopicAuthorizedOperations(authHelper.authorizedOperations(request, new Resource(ResourceType.TOPIC, topicData.name)))
}
}
setTopicAuthorizedOperations(topicMetadata)
}
}
val completeTopicMetadata = unknownTopicIdsTopicMetadata ++
topicMetadata ++ unauthorizedForCreateTopicMetadata ++ unauthorizedForDescribeTopicMetadata
// 获取所有 Broker 列表
val brokers = metadataCache.getAliveBrokerNodes(request.context.listenerName)
trace("Sending topic metadata %s and brokers %s for correlation id %d to client %s".format(completeTopicMetadata.mkString(","),
brokers.mkString(","), request.header.correlationId, request.header.clientId))
val controllerId = {
metadataCache.getControllerId.flatMap {
case ZkCachedControllerId(id) => Some(id)
case KRaftCachedControllerId(_) => metadataCache.getRandomAliveBrokerId
}
}
// 构建 Response 并发送
requestHelper.sendResponseMaybeThrottle(request, requestThrottleMs =>
MetadataResponse.prepareResponse(
requestVersion,
requestThrottleMs,
brokers.toList.asJava,
clusterId,
controllerId.getOrElse(MetadataResponse.NO_CONTROLLER_ID),
completeTopicMetadata.asJava,
clusterAuthorizedOperations
))
}