简介
使用场景
- 异步处理(可以更快地返回结果,减少等待,自然实现了步骤之间的并发,提升系统总体的性能)
- 流量控制(隔离网关和后端服务,以达到流量控制和保护后端服务的目的)
- 服务解耦
- 作为发布 / 订阅系统实现一个微服务级系统间的观察者模式
- 连接流计算任务和数据
- 用于将消息广播给大量接收者
问题和局限性
- 引入消息队列带来的延迟问题
- 增加了系统的复杂度
- 可能产生数据不一致的问题
基本概念
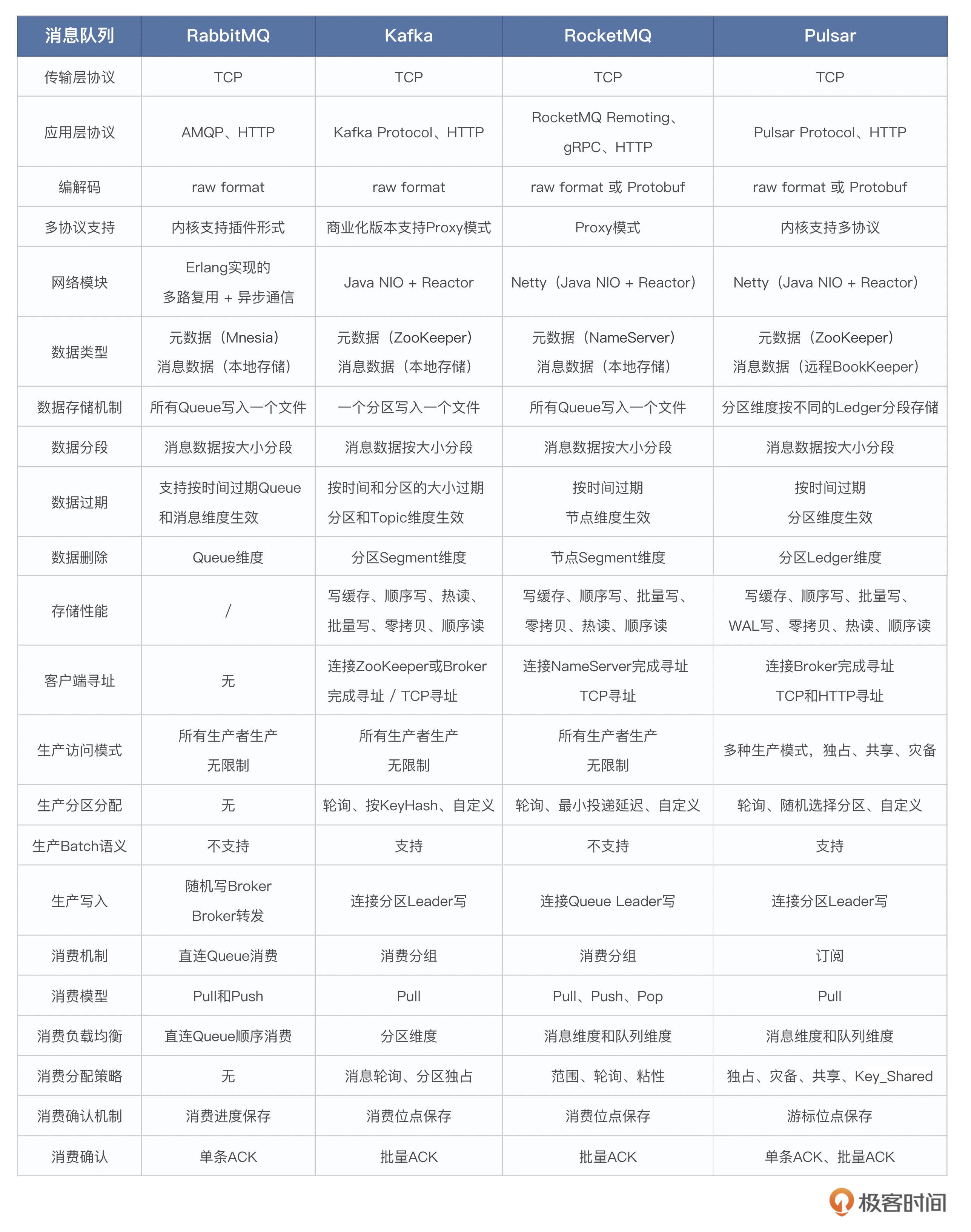
架构层面
- Broker:Broker 本质上是一个进程,比如 RocketMQ 的 Broker 就是指 RocketMQ Server 启动成功后的一个进程。在实际部署过程中,通常一个物理节点只会起一个进程,所以大部分情况下 Broker 就表示一个节点,但是在一些特殊场景下,一个物理节点中也可以起多个进程,就表示一台节点有多个 Broker。
- Topic(主题):在大部分消息队列中,Topic 都是指用来组织分区关系的一个逻辑概念。通常情况下,一个 Topic 会包含多个分区。但是 RabbitMQ 是一个例外,Topic 是指具体某一种主题模式。
- Partition/Queue/MessageQueue(分区/分片):用来表示数据存储的最小单位。一般可以直接将消息写入到一个分区中,也可以将消息写入到 Topic,再分发到具体某个分区。一个 Topic 通常会包含一个或多个分区。
- Producer(生产者): 生产者指消息的发送方,即发送消息的客户端,也叫生产端。
- Consumer(消费者):消费者指消息的接收方,即接收消息的客户端,也叫消费端。
- ConsumerGroup/Subscription(消费分组/订阅):一般情况下,消息队列中消费分组和订阅是同一个概念。它是用来组织消费者和分区关系的逻辑概念,也有保存消费进度的作用。
- Message(消息):指一条真实的业务数据,消息队列的每条数据一般都叫做一条消息。
- Offset/ConsumerOffset/Cursor(位点/消费位点/游标):指消费者消费分区的进度,即每个消费者都会去消费分区,为了避免重复消费进度,都会保存消费者消费分区的进度信息。
- ACK/OffsetCommit(确认/位点提交):确认和位点提交一般都是指提交消费进度的操作,即数据消费成功后,提交当前的消费位点,确保不重复消费。
- Leader/Follower(领导者/追随者,主副本/从副本):Leader 和 Follower 一般是分区维度副本的概念,即集群中的分区一般会有多个副本。此时就会有主从副本的概念,一般是一个主副本配上一个或多个从副本。
- Segment(段/数据分段):段是指消息数据在底层具体存储时,分为多个文件存储时的文件,这个文件就叫做分区的数据段。即比如每超过 1G 的文件就新起一个文件来存储,这个文件就是 Segment。基本所有的消息队列都有段的概念,比如 Kakfa 的 Segment、Pulsar 的 Ledger 等等。
- StartOffset/EndOffset(起始位点/结束位点):起始位点和结束位点是分区维度的概念。即数据是顺序写入到分区的,一般从 0 的位置开始往后写,此时起始位点就是 0。因为数据有过期的概念,分区维度较早的数据会被清理。此时起始位点就会往后移,表示当前阶段最早那条有效消息的位点。结束位点是指最新的那条数据的写入位置。因为数据一直在写入分区,所以起始位点和结束位点是一直动态变化的。
功能层面
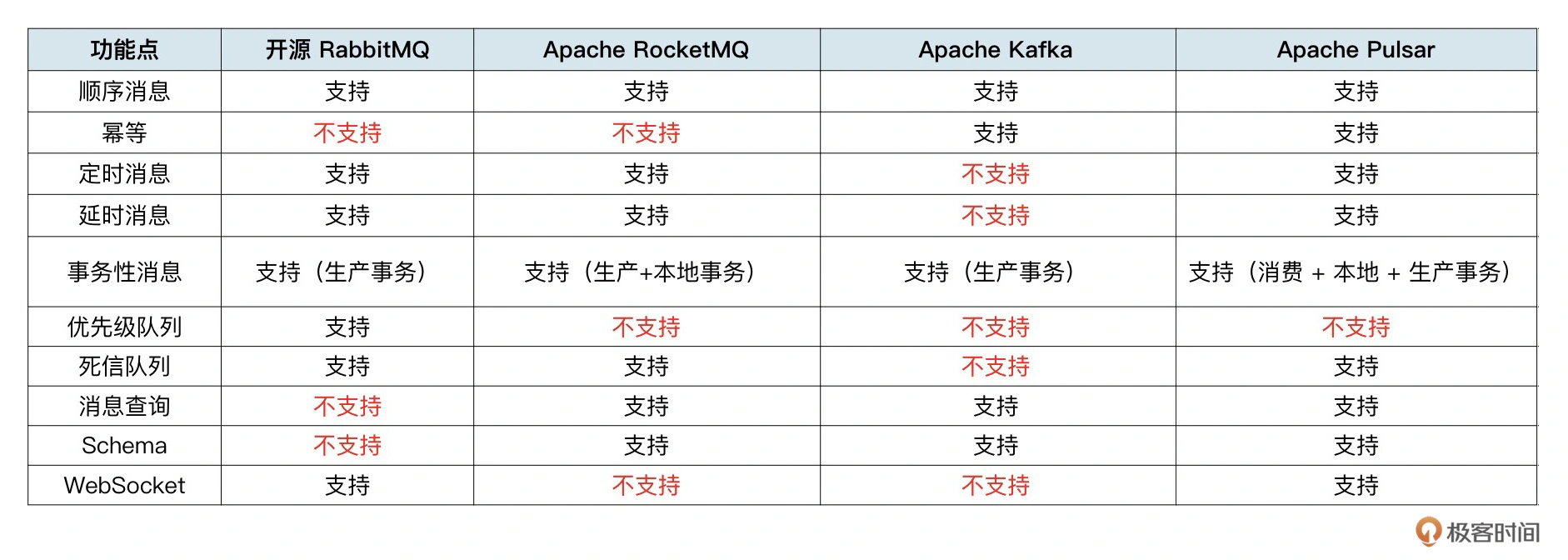
- 顺序消息:是指从生产者和消费者的视角来看,生产者按顺序写入 Topic 的消息,在消费者这边能按生产者写入的顺序消费到消息。
- 延时消息/定时消息:都是指生产者发送消息到 Broker 时,可以设置这条消息在多久后能被消费到。延时的意思是指以 Broker 收到消息的时间为准,定时是指可以指定消息在设置的时间才能被看到。
- 事务消息:消息队列的事务因为在不同的消息队列中的实现方式不一样,所以定义也不太一样。一般指发送一批消息,要么同时成功,要么同时失败。
- 消息重试:消息重试分为生产者重试和消费者重试。生产者重试是指当消息发送失败后,可以设置重试逻辑,比如重试几次、多久后重试、重试间隔多少。消费者重试是指当消费的消息处理失败后,会自动重试消费消息。
- 消息回溯:是指当允许消息被多次消费,即某条消息消费成功后,这条消息不会被删除,还能再重复到这条消息。
- 广播消费:一条消息能被很多个消费者消费到。
- 死信队列:死信队列是一个功能,不是一个像分区一样的实体概念。它是指当某条消息无法处理成功时,则把这条消息写入到死信队列,将这条消息保存起来,从而可以处理后续的消息的功能。大部分情况下,死信队列在消费端使用得比较多,即消费到的消息无法处理成功,则将数据先保存到死信队列,然后可以继续处理其他消息。在生产的时候也会有死信队列的概念,即某条消息无法写入 Topic,则可以先写入到死信队列。从功能上来看,死信队列的功能业务也可以自己去实现。消息队列的 SDK 已经集成了这部分功能,从而让业务使用起来就很简单。
- 优先级队列:优先级队列是指可以给在一个分区或队列中的消息设置权重,权重大的消息能够被优先消费到。大部分情况下,消息队列的消息处理是 FIFO 先进先出的规则。此时如果某些消息需要被优先处理,基于这个规则就无法实现。所以就有了优先级队列的概念,优先级是消息维度设置的。
- 消息过滤:是指可以给每条消息打上标签,在消费的时候可以根据标签信息去消费消息。
- 消息过期/删除(TTL):是指消息队列中的消息会在一定时间或者超过一定大小后会被删除。因为消息队列主要是缓冲作用,所以一般会要求消息在一定的策略后会自动被清理。
- 消息轨迹:是指记录一条消息从生产端发送、服务端保存、消费端消费的全生命周期的流程信息。用来追溯消息什么时候被发送、是否发送成功、什么时候发送成功、服务端是否保存成功、什么时候保存成功、被哪些消费者消费、是否消费成功、什么时候被消费等等信息。
- 消息查询:是指能够根据某些信息查询到消息队列中的信息。比如根据消息 ID 或根据消费位点来查询消息,可以理解为数据库里面的固定条件的 select 操作。
- 消息压缩:是指生产端发送消息的时候,是否支持将消息进行压缩,以节省物理资源(比如网卡、硬盘)。压缩可以在 SDK 完成,也可以在 Broker 完成,并没有严格限制。通常来看,压缩在客户端完成会比较合理。
- 多租户:是指同一个集群是否有逻辑隔离,比如一个物理集群能否创建两个名称都为 test 的主题。此时一般会有一个逻辑概念 Namespace(命名空间)和 Tenant(租户)来做隔离,一般有这两个概念的就是支持多租户。
- 消息持久化:是指消息发送到 Broker 后,会不会持久化存储,比如存储到硬盘。有些消息队列为了保证性能,只会把消息存储在内存,此时节点重启后数据就会丢失。
- 消息流控:是指能否对写入集群的消息进行限制。一般会支持 Topic、分区、消费分组、集群等维度的限流。
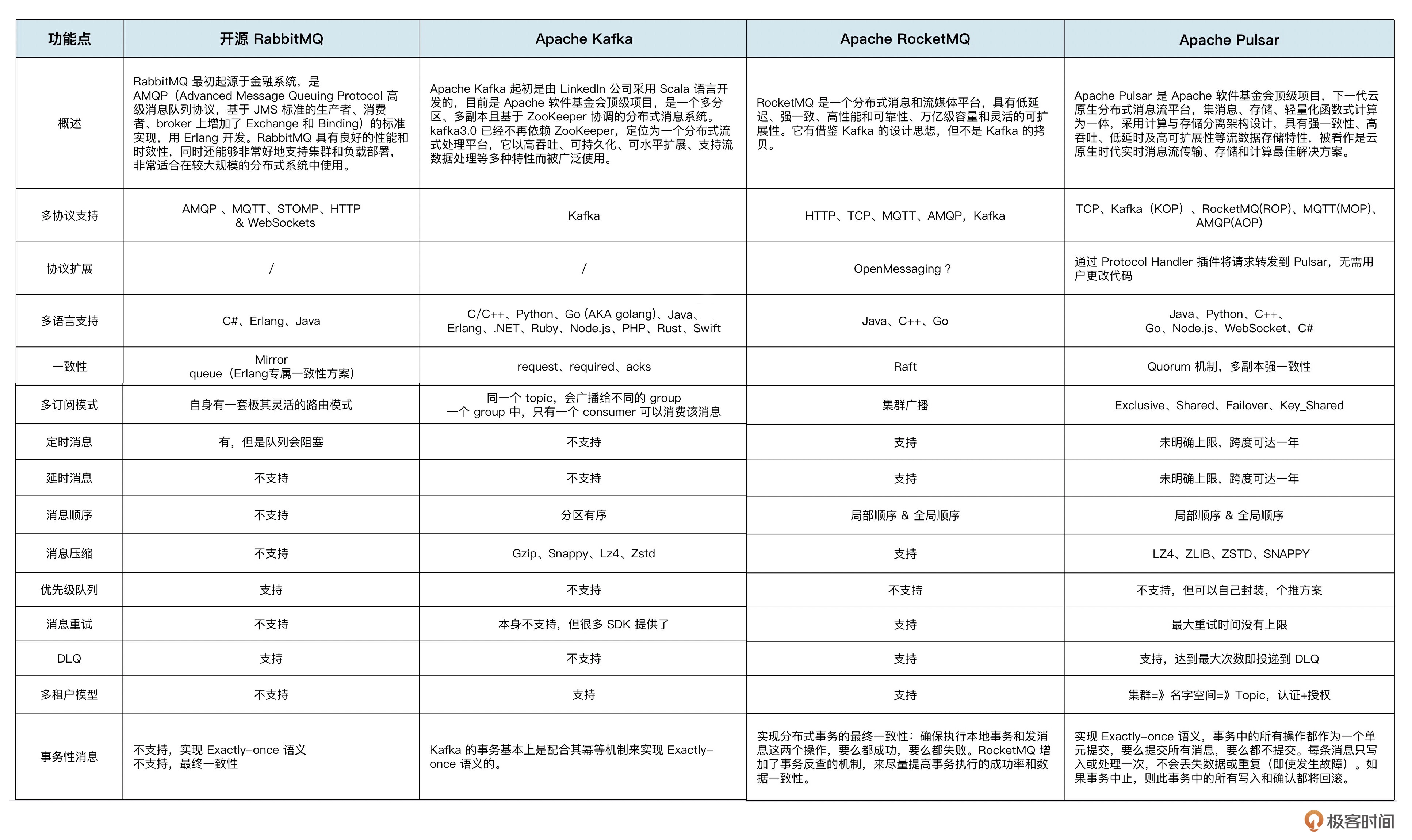
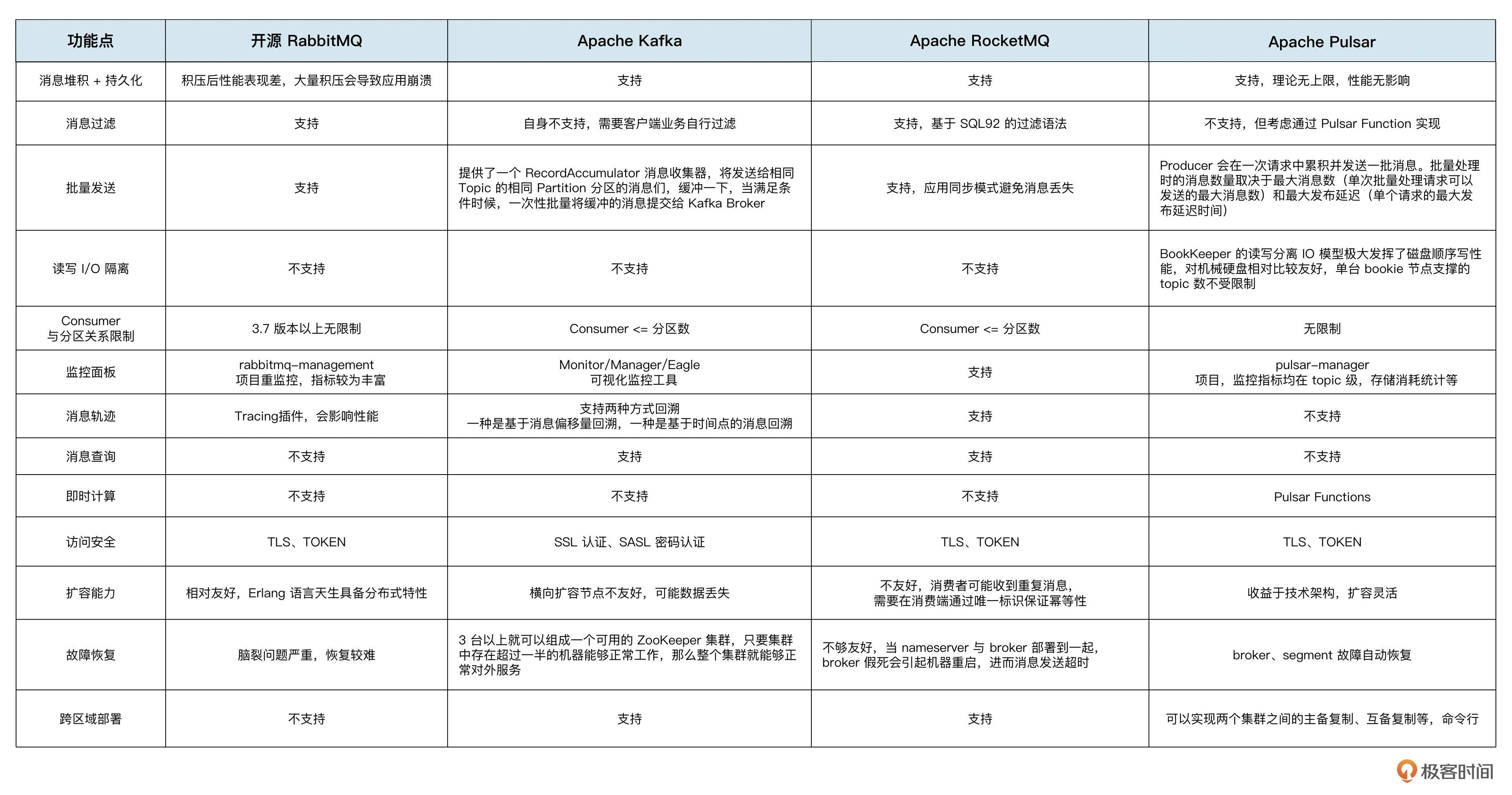
常见的开源的消息队列中间件
RabbitMQ
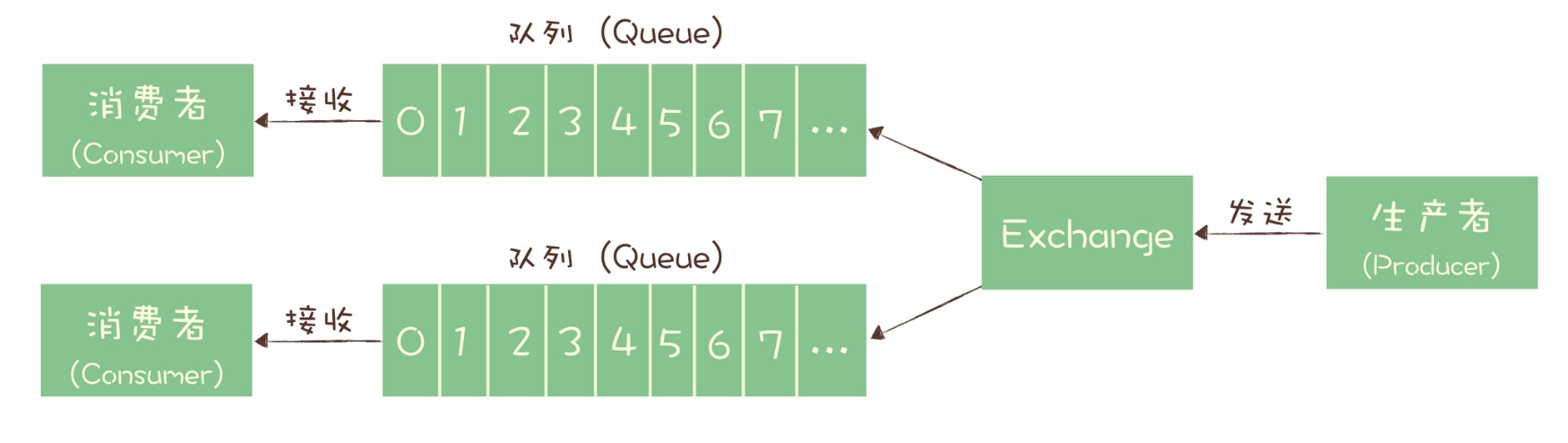
消息模型
Exchange 位于生产者和队列之间,生产者并不关心将消息发送给哪个队列,而是将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。
优点
- 使用Erlang语言编写的,它最早是为电信行业系统之间的可靠通信设计的,也是少数几个支持 AMQP 协议的消息队列之一。
- 相当轻量级的消息队列,非常容易部署和使用。
- 支持非常灵活的路由配置,和其他消息队列不同的是,它在生产者(Producer)和队列(Queue)之间增加了一个 Exchange 模块,可以理解为交换机,可根据配置的路由规则将生产者发出的消息分发到不同的队列中。
缺点
- 对消息堆积的支持并不好,在它的设计理念里面,消息队列是一个管道,大量的消息积压是一种不正常的情况,应当尽量去避免。当大量消息积压的时候,会导致性能急剧下降。
- 性能是这几个消息队列中最差的,大概每秒钟可以处理几万到十几万条消息。
- 使用的编程语言 Erlang 不仅是非常小众的语言,而且学习曲线非常陡峭。做一些扩展和二次开发,建议慎重考虑可持续维护的问题。
RocketMQ
消息模型
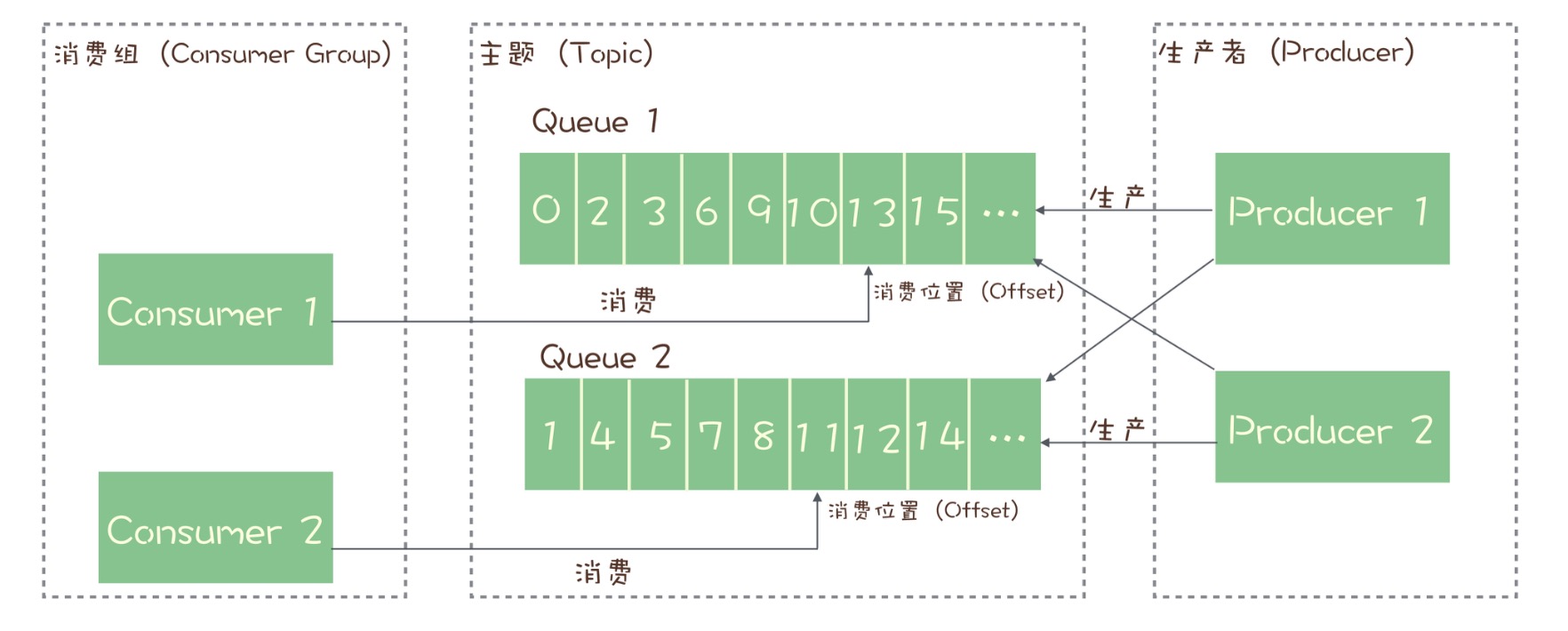
每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费。只在队列上保证消息的有序性,主题层面是无法保证消息的严格顺序的。
订阅者的概念是通过消费组(Consumer Group)来体现的。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,即一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。消费组中包含多个消费者,同一个组内的消费者是竞争消费的关系,每个消费者负责消费组内的一部分消息。如果一条消息被消费者 Consumer1 消费了,那同组的其他消费者就不会再收到这条消息。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。
分布式事务
增加了事务反查的机制来解决事务消息提交失败的问题。
在提交或者回滚事务消息时发生网络异常,RocketMQ 的 Broker 没有收到提交或者回滚的请求,Broker 会定期去 Producer 上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。
为了支撑这个事务反查机制,业务代码需要实现一个反查本地事务状态的接口,告知 RocketMQ 本地事务是成功还是失败。
![]()
优点
- 有非常活跃的中文社区,使用 Java 语言开发,很容易对 RocketMQ 进行扩展或者二次开发。
- 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应。
- 每秒钟大概能处理几十万条消息。
缺点
- 作为国产的消息队列,相比国外的比较流行的同类产品,在国际上还没有那么流行,与周边生态系统的集成和兼容程度要略逊一筹。
Kafka
消息模型
和 RocketMQ 是完全一样的,唯一的区别是,在 Kafka 中,队列这个概念的名称不一样,Kafka 中对应的名称是“分区(Partition)”,含义和功能是没有任何区别的。
分布式事务
直接抛出异常,让用户自行处理。可以在业务代码中反复重试提交,直到提交成功,或者删除之前创建的订单进行补偿。
优点
- 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所有的相关开源软件系统都会优先支持 Kafka。
- 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,拥有超高的性能。尤其是异步收发的性能,大约每秒钟可以处理几十万条消息。
缺点
- Broker使用“先攒一波再一起处理”的设计,同步收发消息的响应时延比较高。
- 当业务场景中,每秒钟消息数量没有那么多的时候,时延反而会比较高,不太适合在线业务场景。
Pulsar
优点
- 分布式发布-订阅消息平台,具有非常灵活的消息模型和直观的客户端 API。
- 分层架构(Broker + BookKeeper),存储计算分离。
- 相比 Kafka,具有更高的吞吐量和更低的延迟。
缺点
- 架构设计复杂(如 Broker + BookKeeper 的分层架构、多租户模型等),其高级功能(如分层存储、事务消息)需要较长时间的学习和实践。
- 社区规模较小,相比 Kafka 的庞大社区和商业支持(如 Confluent),Pulsar 的开发者生态和第三方解决方案仍处于发展阶段。
总结
- RabbitMQ:对消息队列功能和性能都没有很高的要求,只需要一个开箱即用易于维护的产品。
- RocketMQ:低延迟和金融级的稳定性,主要场景是处理在线业务,比如在交易系统中用消息队列传递订单。
- Kafka:处理海量的消息,像收集日志、监控信息或是前端的埋点这类数据,或是应用场景大量使用了大数据、流计算相关的开源产品。
- Pulsar:云原生架构、低延迟和多场景适配性,尤其在金融、游戏、IoT 和全球化业务中表现突出。

确保消息不丢失
检测消息丢失的方法
利用消息队列的有序性来验证是否有消息丢失。
在 Producer 端,给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。
确保消息可靠传递
生产阶段
在编写发送消息代码时,需要注意,正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。
存储阶段
如果对消息的可靠性要求非常高,可以通过配置 Broker 参数来避免因为宕机丢消息。
消费阶段
不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。
消费过程中重复消息的处理
用幂等性解决重复消息问题
在消费端,让消费消息的操作具备幂等性。其任意多次执行所产生的影响均与一次执行的影响相同。从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作。
- 利用数据库的唯一约束实现幂等
- 为更新的数据设置前置条件
- 记录并检查操作
消息积压的处理
优化性能来避免消息积压
发送端性能优化
- 优先检查一下,是不是发消息之前的业务逻辑耗时太多导致的。
- 增加批量或者是增加并发
消费端性能优化
- 要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。
- 在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。