网络基础
tun/tap设备
从Linux文件系统的角度看,tun/tap设备是用户可以用文件句柄操作的字符设备;从网络虚拟化角度看,它是虚拟网卡,一端连着网络协议栈,另一端连着用户态程序。tun表示虚拟的是点对点设备,tap表示虚拟的是以太网设备,这两种设备针对网络包实施不同的封装。
tun/tap设备可以将TCP/IP协议栈处理好的网络包发送给任何一个使用tun/tap驱动的进程,由进程重新处理后发到物理链路中。tun/tap设备就像是埋在用户程序空间的一个钩子,可以很方便地将对网络包的处理程序挂在这个钩子上,OpenVPN、Vtun、flannel都是基于它实现隧道包封装的。
工作原理
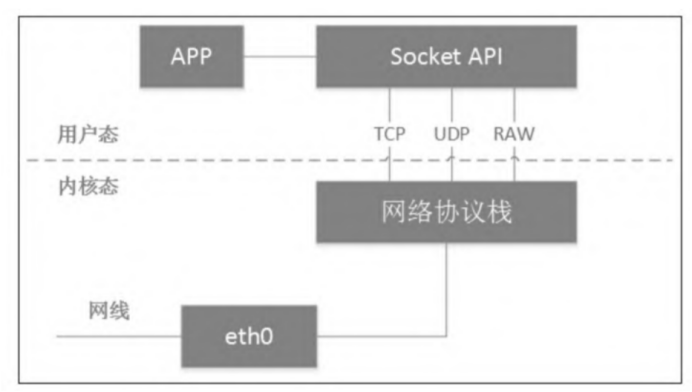
一个经典的、通过Socket调用实现用户态和内核态数据交互的过程。物理网卡从网线接收数据后送达网络协议栈,而进程通过Socket创建特殊套接字,从网络协议栈读取数据。
从网络协议栈的角度看,tun/tap设备这类虚拟网卡与物理网卡并无区别。只是对tun/tap设备而言,它与物理网卡的不同表现在它的数据源不是物理链路,而是来自用户态,这也是tun/tap设备的最大价值所在。
tun/tap设备其实就是利用Linux的设备文件实现内核态和用户态的数据交互,而访问设备文件则会调用设备驱动相应的例程,要知道设备驱动也是内核态和用户态的一个接口。
工作模式
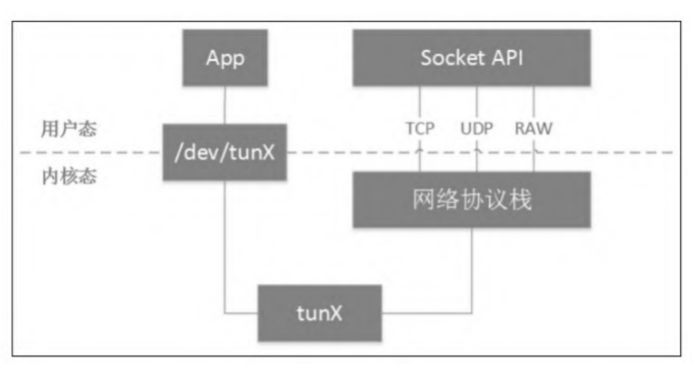
普通的物理网卡通过网线收发数据包,而tun设备通过一个设备文件(/dev/tunX)收发数据包。所有对这个文件的写操作会通过tun设备转换成一个数据包传送给内核网络协议栈。当内核发送一个包给tun设备时,用户态的进程通过读取这个文件可以拿到包的内容。当然,用户态的程序也可以通过写这个文件向tun设备发送数据。
tap设备与tun设备的工作原理完全相同,区别在于:
- tun设备的/dev/tunX文件收发的是IP包,因此只能工作在L3,无法与物理网卡做桥接,但可以通过三层交换(例如ip_forward)与物理网卡连通;
- tap设备的/dev/tapX文件收发的是链路层数据包,可以与物理网卡做桥接。
Linux隧道网络的代表:VXLAN
VXLAN(Virtual eXtensible LAN,虚拟可扩展的局域网),是一种虚拟化隧道通信技术。它是一种overlay(覆盖网络)技术,通过三层的网络搭建虚拟的二层网络。
VXLAN是在底层物理网络(underlay)之上使用隧道技术,依托UDP层构建的overlay的逻辑网络,使逻辑网络与物理网络解耦,实现灵活的组网需求。
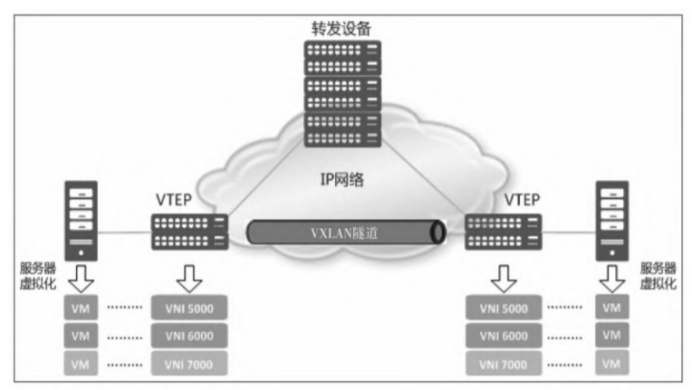
- VTEP(VXLAN Tunnel Endpoints):VXLAN网络的边缘设备,用来进行VXLAN报文的处理(封包和解包)。VTEP可以是网络设备(例如交换机),也可以是一台机器(例如虚拟化集群中的宿主机);
- VNI(VXLAN Network Identifier):VNI是每个VXLAN的标识,是个24位整数,因此最大值是2^24=16777216。如果一个VNI对应一个租户,那么理论上VXLAN可以支撑千万级别的租户。
Kubernetes网络基础
IP地址分配
- 系统会从集群的VPC网络为每个节点分配一个IP地址。该节点IP用于提供从控制组件(如Kube-proxy和Kubelet)到Kubernetes Master的连接;
- 系统会为每个Pod分配一个地址块内的IP地址。用户可以选择在创建集群时通过–pod-cidr指定此范围;
- 系统会从集群的VPC网络为每项服务分配一个IP地址(称为ClusterIP)。大部分情况下,该VPC与节点IP地址不在同一个网段,而且用户可以选择在创建集群时自定义VPC网络。
Pod出站流量
Pod到Pod
在Kubernetes集群中,每个Pod都有自己的IP地址,运行在Pod内的应用都可以使用标准的端口号,不用重新映射到不同的随机端口号。所有的Pod之间都可以保持三层网络的连通性,比如可以相互ping对方,相互发送TCP/UDP/SCTP数据包。CNI就是用来实现这些网络功能的标准接口。
Pod到Service
Pod的生命周期很短暂,但客户需要的是可靠的服务,因此Kubernetes引入了新的资源对象Service,其实它就是Pod前面的4层负载均衡器。Service总共有4种类型,其中最常用的类型是ClusterIP,这种类型的Service会自动分配一个仅集群内部可以访问的虚拟IP。
Kubernetes通过Kube-proxy组件实现这些功能,每台计算节点上都运行一个Kubeproxy进程,通过复杂的iptables/IPVS规则在Pod和Service之间进行各种过滤和NAT。
Pod到集群外
从Pod内部到集群外部的流量,Kubernetes会通过SNAT来处理。SNAT做的工作就是将数据包的源从Pod内部的IP:Port替换为宿主机的IP:Port。当数据包返回时,再将目的地址从宿主机的IP:Port替换为Pod内部的IP:Port,然后发送给Pod。当然,中间的整个过程对Pod来说是完全透明的,它们对地址转换不会有任何感知。
网络架构综述
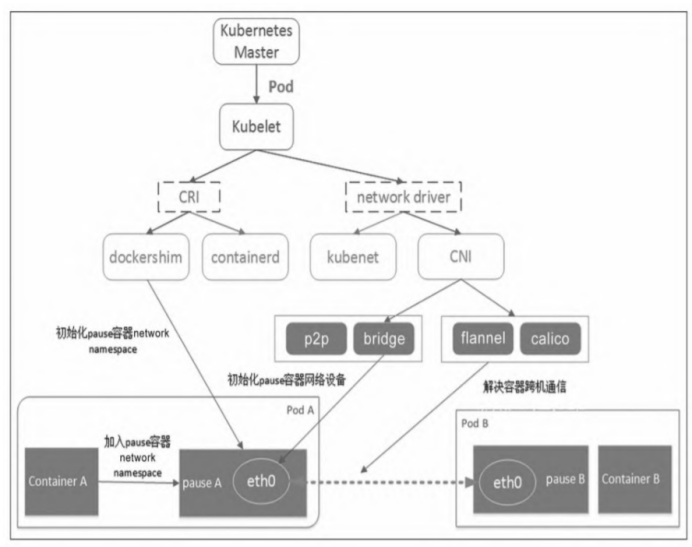
- 当用户在Kubernetes的Master里创建了一个Pod后,Kubelet观察到新Pod的创建,于是首先调用CRI(后面的runtime实现,比如dockershim、containerd等)创建Pod内的若干个容器。
- 在这些容器里,第一个被创建的pause容器,作用就是占用一个Linux的network namespace,且不初始化网络协议栈。
- Pod内其他用户容器通过加入这个network namespace的方式共享同一个network namespace。
- CNI主要负责容器的网络设备初始化工作,比如给pause容器内的eth0分配IP等。
主机内组网模型
Kubernetes经典的主机内组网模型是veth pair+bridge的方式。
当Kubernetes调度Pod在某个节点上运行时,它会在该节点的Linux内核中为Pod创建network namespace,供Pod内所有运行的容器使用。
Kubernetes使用veth pair将容器与主机的网络协议栈连接起来,从而使数据包可以进出Pod。容器放在主机根network namespace中veth pair的一端连接到Linux网桥,可让同一节点上的各Pod之间相互通信。
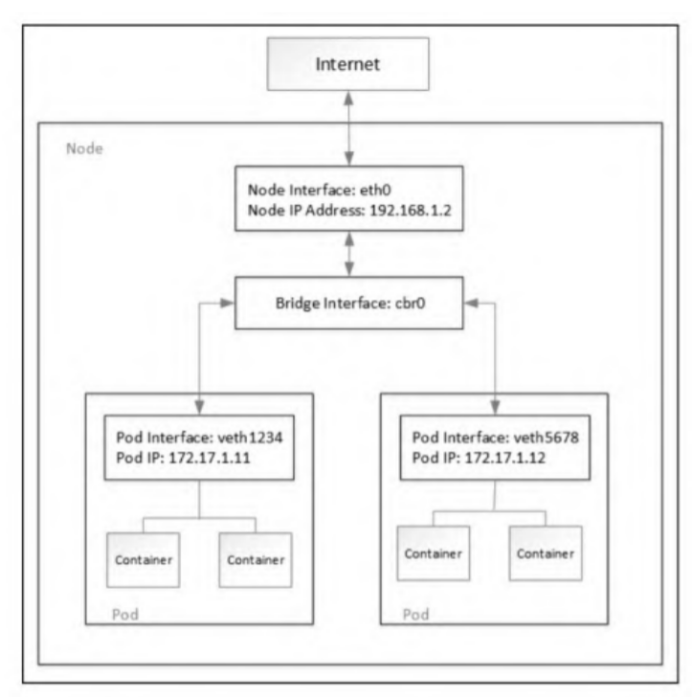
如果Kubernetes集群发生节点升级、修改Pod声明式配置、更新容器镜像或节点不可用,那么Kubernetes就会删除并重新创建Pod。在大部分情况下,Pod创建会导致容器IP发生变化。也有一些CNI插件提供Pod固定IP的解决方案,例如Weave、Calico等
跨节点组网模型
bridge跨机通信网络模型
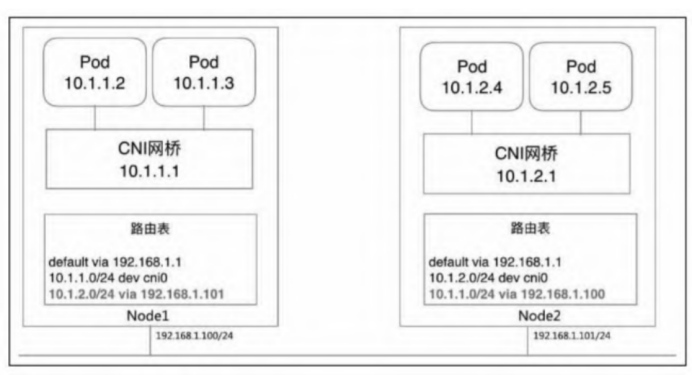
Node1上Pod的网段是10.1.1.0/24,接的Linux网桥是10.1.1.1,Node2上Pod的网段是10.1.2.0/24,接的Linux网桥是10.1.2.1,接在同一个网桥上的Pod通过局域网广播通信。Node1上的路由表的第二条是
1
10.1.1.0/24 dev cni0
所有目的地址是本机上Pod的网络包,都发到cni0这个Linux网桥,进而广播给Pod。
注意看第三条路由规则
1
10.1.2.0/24 via 192.168.1.101
10.1.2.0/24是Node2上Pod的网段,192.168.1.101又恰好是Node2的IP。意思是,目的地址是10.1.2.0/24的网络包,发到Node2上。
Node2上面的第二条路由信息:
1
10.1.2.0/24 dev cni0
这个包会被接着发给Node2上的Linux网桥cni0,再广播给目标Pod。回程报文同理(走一条逆向的路径)。
bridge网络本身不解决容器的跨机通信问题,需要显式地书写主机路由表,映射目标容器网段和主机IP的关系,集群内如果有N个主机,需要N-1条路由表项。
overlay跨机通信网络模型
overlay网络是构建在物理网络之上的一个虚拟网络,其中VXLAN是主流的overlay标准。VXLAN就是用UDP包头封装二层帧,即所谓的MAC in UDP。
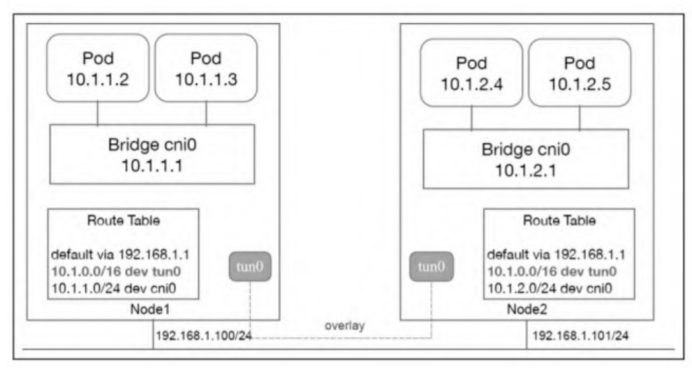
和bridge网络类似,Pod同样接在Linux网桥上,目的地址落在本机Pod网段的网络包同样发给Linux网桥cni0。不同的是,目的Pod在其他节点上的路由表规则
1
10.1.0.0/16 dev tun0
这次是直接发给本机的tun/tap设备tun0,而tun0就是overlay隧道网络的入口。集群内所有机器都只需要这么一条路由表,不需要像bridge网络那样,写N-1条路由表项。如何将网络包正确地传递到目标主机的隧道口另一端呢?以flannel的实现为例,它会借助一个分布式的数据库,记录目的容器IP与所在主机的IP的映射关系,而且每个节点上都会运行一个agent。例如,flanneld会监听在tun0上进行的封包和解包操作。例如,Node1上的容器发包给Node2上的容器,flanneld会在tun0处将一个目的地址是192.168.1.101:8472的UDP包头(校验和置成0)封装到这个包的外层,然后借着主机网络顺利到达Node2。监听在Node2的tun0上的flanneld捕获这个特殊的UDP包(检验和为0),知道这是一个overlay的封包,于是解开UDP包头,将它发给本机的Linux网桥cni0,进而广播给目的容器。
bridge和overlay是Kubernetes最早采用的跨机通信方案,但随着集成Weave和Calico等越来越多的CNI插件,Kubernetes也支持虚拟路由等方式。
Pod的hosts文件和hostname
当一个Pod被创建后,默认情况下,hosts文件只包含IPv4和IPv6的样板内容。在Kubernetes 1.7版本以后,Kubernetes提供downward API,支持用户通过PodSpec的HostAliases字段添加这些自定义的条目。
注:如果Pod启用了hostNetwork(即使用主机网络),那么将不能使用HostAliases特性,因为Kubelet只管理非hostNetwork类型Pod的hosts文件
Docker使用UTS namespace进行主机名(hostname)隔离,而Kubernetes的Pod也继承了Docker的UTS namespace隔离技术,即Pod之间主机名相互隔离,但Pod内容器分享同一个主机名。
Docker主要有两种使用UTS namespace的用法:
- 第一种是docker run –uts=”” busybox。这种用法在创建容器的同时会新创建一个UTS namespace;
- 第二种是docekr run –uts=”host” busybox。这种用法在创建容器的同时会使用物理机的UTS namespace。 除此之外,Kubernetes在处理UTS namespace时也会考虑Pod的网络模式。
如果Kubelet判断Pod使用宿主机网络(即host-Network),则会将UTS的mode设置为“host”,也就是使用物理机的UTS namespace。因此,如果这时容器修改主机名,则会影响宿主机的主机名。
如果容器想要修改主机名(通过hostname命令),则需要privileged权限。修改容器主机名后,容器重启或被Kubelet重建都会恢复成原来的主机名,主要原因是容器重启会导致创建新的UTS namespace。
一个Pod内如果有多个容器,修改任意一个容器的hostname都会影响其他容器,因为Pod共享UTS namespace。
Pod的核心:pause容器
原则上,任何人都可以配置Docker来控制容器组之间的共享级别——只需创建一个父容器,并创建与父容器共享资源的新容器,然后管理这些容器的生命周期。在Kubernetes中,pause容器被当作Pod中所有容器的“父容器”,并为每个业务容器提供以下功能:
- 在Pod中,它作为共享Linux namespace(Network、UTS等)的基础;
- 启用PID namespace共享,它为每个Pod提供1号进程,并收集Pod内的僵尸进程。
pause容器运行一个非常简单的进程,它不执行任何功能,一启动就永远把自己阻塞住了(见pause()系统调用)。它扮演PID 1的角色,并在子进程成为“孤儿进程”的时候,通过调用wait()收割这些僵尸子进程。这样就不用担心Pod的PID namespace里会堆满僵尸进程了。
从集群内访问服务
在Kubernetes中,用户可以为任何Kubernetes资源分配成为Labels(标签)的任意键值。Kubernetes使用Labels将多个相关的Pod组合成一个逻辑单元,称为Service。Service具有稳定的IP地址(区别于容器不固定的IP地址)和端口,并会在一组匹配的后端Pod之间提供负载均衡,匹配的条件就是Service的Label Selector与Pod的Labels相匹配。
Service详解
Kubernetes的Service代表的是Kubernetes后端服务的入口,它主要包含服务的访问IP(虚IP)和端口,工作在L4。
到Service通过Label Selector选择与之匹配的Pod。那么被Service选中的Pod,当它们运行且能对外提供服务后,Kubernetes的Endpoints Controller会生成一个新的Endpoints对象,记录Pod的IP和端口,解决了后端实例健康检查问题。另外,Service的访问IP和Endpoints/Pod IP都会在Kubernetes的DNS服务器里存储域名和IP的映射关系,因此用户可以在集群内通过域名的方式访问Service和Pod。
Kubernetes会从集群的可用服务IP池中为每个新创建的服务分配一个稳定的集群内访问IP地址,称为Cluster IP。Kubernetes还会通过添加DNS条目为Cluster IP分配主机名。Cluster IP和主机名在集群内是独一无二的,并且在服务的整个生命周期内不会更改。只有将服务从集群中删除,Kubernetes才会释放Cluster IP和主机名。用户可以使用服务的Cluster IP或主机名访问正常运行的Pod。
Kubernetes使用Kube-proxy组件管理各服务与之后端Pod的连接,该组件在每个节点上运行。Kube-proxy是一个基于出站流量的负载平衡控制器,它监控Kubernetes API Service并持续将服务IP(包括Cluster IP等)映射到运行状况良好的Pod,落实到主机上就是iptables/IPVS等路由规则。访问服务的IP会被这些路由规则直接DNAT到Pod IP,然后走底层容器网络送到对应的Pod。
Kubernetes Service能够支持TCP、UDP和SCTP三种协议,默认是TCP协议。
Service的三个port
- port表示Service暴露的服务端口,也是客户端访问用的端口,例如Cluster IP:port是提供给集群内部客户访问Service的入口。需要注意的是,port不仅是Cluster IP上暴露的端口,还可以是external IP和LoadBalancer IP。Service的port并不监听在节点IP上,即无法通过节点IP:port的方式访问Service。
- NodePort是Kubernetes提供给集群外部访问Service入口的一种方式(另一种方式是Load Balancer),所以可以通过Node IP:nodePort的方式提供集群外访问Service的入口。需要注意的是,集群外指的是Pod网段外,例如Kubernetes节点或因特网。
- targetPort是应用程序实际监听Pod内流量的端口,从port和NodePort上到来的数据,最终经过Kube-proxy流入后端Pod的targetPort进入容器。
Service类型
Cluster IP
Cluster IP是默认类型,自动分配集群内部可以访问的虚IP。创建一个Service,只要不做特别指定,都是Cluster IP类型。
Cluster IP主要在每个node节点使用iptables,将发向Cluster IP对应端口的数据转发到后端Pod中。
NodePort
NodePort为Service在Kubernetes集群的每个节点上分配一个真实的端口,即NodePort。集群内/外部可基于集群内任何一个节点的IP:NodePort的形式访问Service。NodePort支持TCP、UDP、SCTP,默认端口范围是30000-32767。
NodePort的实现机制是Kube-proxy会创建一个iptables规则,所有访问本地NodePort的网络包都会被直接转发至后端Port。NodePort会在主机上打开(但不监听)一个实际的端口,某个NodePort被打开后,主机上其他进程将无法再使用该端口,除非Service被删除该端口才会被释放。
Load Balancer
Load Balancer(简称LB)类型的Service需要Cloud Provider的支持。
Headless Service
Headless Services是一种特殊的service,其spec:clusterIP表示为None。这样在实际运行时就不会被分配ClusterIP,而是通过解析service的DNS,返回所有Pod的地址和DNS,让客户端自行要通过负载策略完成负载均衡。 headless services一般结合StatefulSet来部署有状态的应用,statefulset管理的pod提供固定的DNS名称pod-name.service-headless-name.namespace.svc.cluster-domain。
访问本地服务
当访问NodePort或Load Balancer类型Service的流量到节点时,流量可能会被转发到其他节点上的Pod。要指定流量必须转到同一节点上的Pod,可以将serviceSpec.externalTrafficPolicy设置为Local(默认是Cluster)。
将externalTrafficPolicy设置为Local时,负载平衡器仅将流量发送到具有属于服务的正常Pod所在的节点。每个节点上的Kube-proxy都健康运行,检查服务器对外提供该节点上的Endpoint信息,以便系统确定哪些节点具有适当的Pod。
externalTrafficPolicy设置为Local只支持NodePort和Load Balancer的Service,不支持Cluster IP。原因在于externalTrafficPolicy的设定是当流量到达确定的节点后,再由Kube-proxy在该节点上找Service的Endpoint。有些节点上存在Service Endpoint,有些则没有,再配合Kube-proxy的健康检查就能确定哪些节点上有符合要求的后端Pod。访问NodePort和Load Balancer都能指定节点,但Cluster IP无法指定节点,因此Service流量就永远出不了发起访问的客户端的那个节点。
Service实现细节
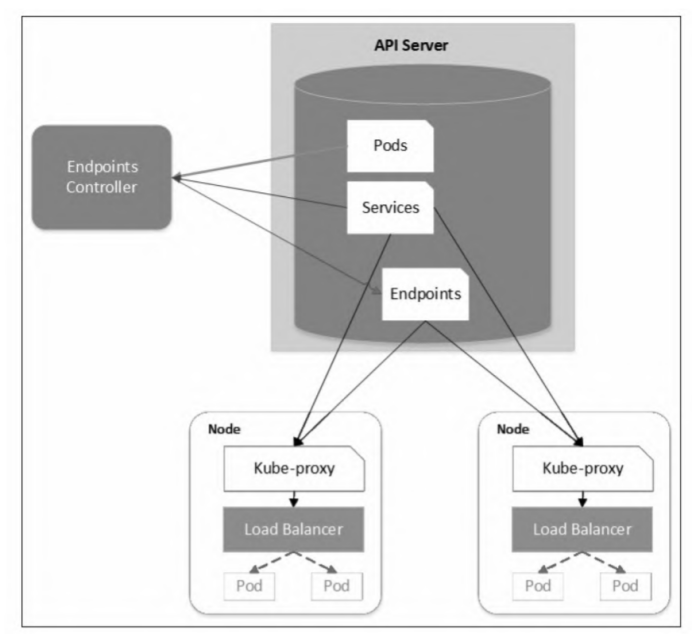
当用户创建Service和对应的后端Pod时,Endpoints Controller会监控Pod的状态变化,当Pod处于Running且准备就绪状态时,Endpoints Controller会生成Endpoints对象。
运行在每个节点上的Kube-proxy会监控Service和Endpoints的更新, 并调用其Load Balancer模块在主机上刷新路由转发规则。每个Pod都可以通过Liveness Probe和Readiness probe探针解决健康检查问题,当有Pod处于非准备就绪状态时,Kube-proxy会删除对应的转发规则。需要注意的是,Kube-proxy的Load Balancer模块并不那么智能,如果转发的Pod不能正常提供服务,它不会重试或尝试连接其他Pod。
Kube-proxy的Load Balancer模块实现有userspace、iptables和IPVS三种,当前主流的实现方式是iptables和IPVS。随着iptables在大规模环境下暴露出了扩展性和性能问题(iptables难以扩展到支持成千上万的服务,它纯粹是为防火墙而设计的,并且底层路由表的实现是链表,对路由规则的增删改查操作都涉及遍历一次链表。),越来越多的厂商开始使用IPVS模式。
Kube-proxy的转发模式可以通过启动参数–proxy-mode进行配置,有userspace、iptables、ipvs等可选项。
userspace模式
Kube-proxy的userspace模式是通过Kube-proxy用户态程序实现Load Balancer的代理服务。userspace模式是Kube-proxy 1.0之前版本的默认模式。由于转发发生在用户态,效率自然不太高,而且容易丢包。
iptables和IPVS模式都依赖Linux内核的能力,尤其是IPVS,而且iptables和IPVS都要求较高版本的内核和iptables版本。那些使用低版本内核的操作系统(例如SUSE 11)用不了iptables和IPVS模式,但又希望拥有基本的服务转发能力,这时userspace模式就派上用场了。
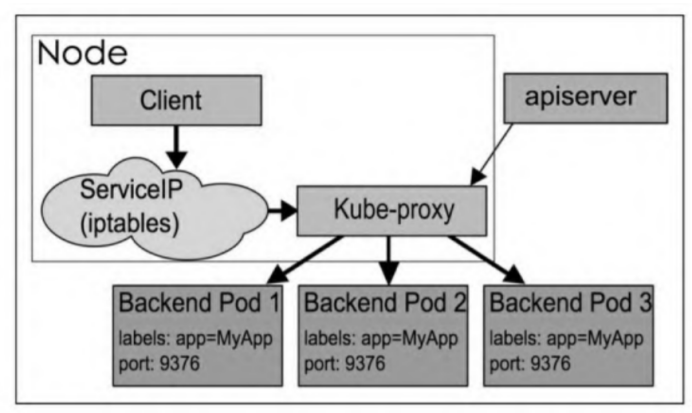
在userspace模式下,访问服务的请求到达节点后首先会进入内核iptables,然后回到用户空间,由Kube-proxy完成后端Pod的选择,并建立一条到后端Pod的连接,完成代理转发工作。这样流量从用户空间进出内核将带来不小的性能损耗。
Kube-proxy进程只监听一个端口,而且这个端口并不是服务的访问端口也不是服务的NodePort,因此需要一层iptables把访问服务的连接重定向给Kube-proxy进程的一个临时端口。Kube-proxy在代理客户端请求时会开放一个临时端口,以便后端Pod的响应返回给Kube-proxy,然后Kube-proxy再返回给客户端。
iptables模式
从Kubernetes 1.1版本开始,增加了iptables模式,在1.2版本中它正式替代userspace模式成为默认模式。
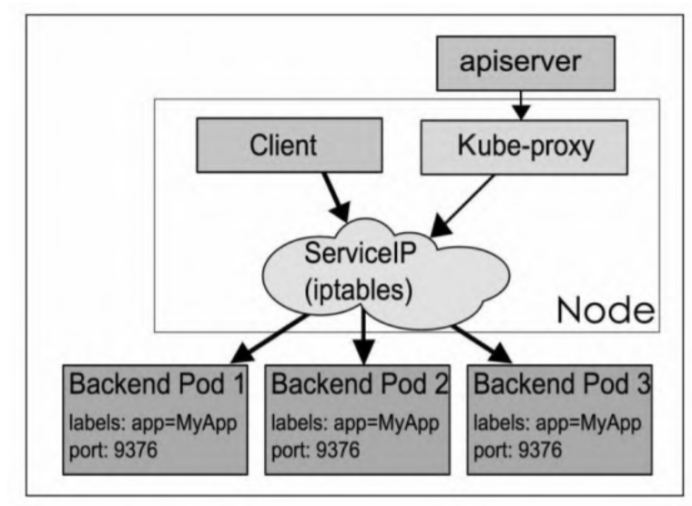
iptables模式与userspace模式最大的区别在于,Kube-proxy利用iptables的DNAT模块,实现了Service入口地址到Pod实际地址的转换,免去了一次内核态到用户态的切换。
Kube-proxy的iptables模式采用随机数实现了服务的负载均衡。iptables模式与userspace模式相比虽然在稳定性和性能上均有不小的提升,但因为iptable使用NAT完成转发,也存在不可忽视的性能损耗。另外,当集群中存在上万服务时,Node上的iptables rules会非常庞大,对管理是个不小的负担,性能还会大打折扣。
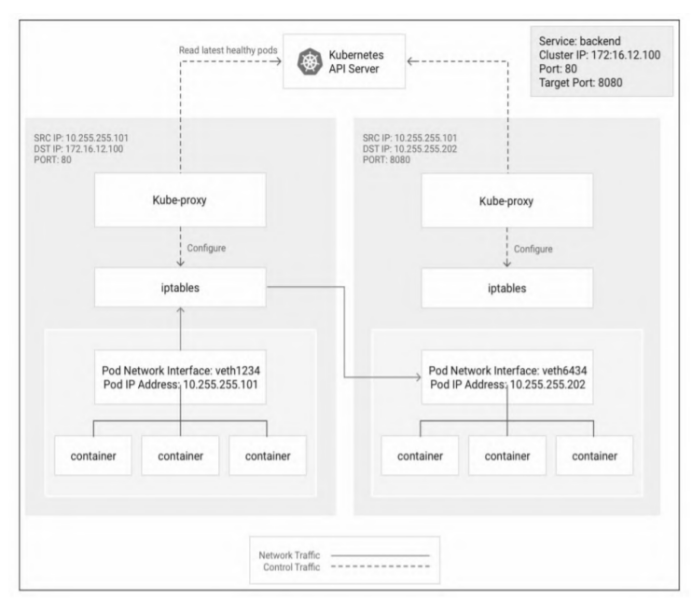
iptables模式最主要的链是KUBE-SERVICES、KUBESVC-和KUBE-SEP-。
- KUBE-SERVICES链是访问集群内服务的数据包入口点,它会根据匹配到的目标IP:port将数据包分发到相应的KUBE-SVC-*链;
- KUBE-SVC-链相当于一个负载均衡器,它会将数据包平均分发到KUBE-SEP-链。每个KUBE-SVC-链后面的KUBE-SEP-链都和Service的后端Pod数量一样;
- KUBE-SEP-*链通过DNAT将连接的目的地址和端口从Service的IP:port替换为后端Pod的IP:port,从而将流量转发到相应的Pod。
既然利用iptables做了一次DNAT,为了保证回程报文能够顺利返回,需要做一次SNAT。
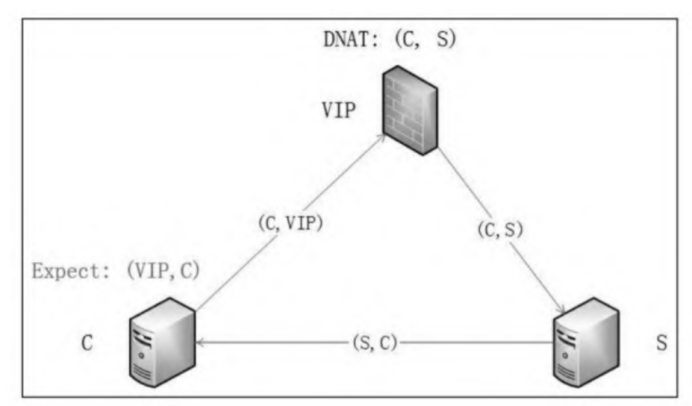
客户端(C)发起对一个服务(S)的访问,假设目的地址是(C,VIP),那么客户端期待得到的回程报文的源地址是VIP,即回程报文的源和目的地址对应该是(VIP,C)。当网络报文经过网关(Linux内核的netfilter,包括iptables和IPVS director)进行一次DNAT后,报文的源和目的地址对被修改成了(C,S)。当报文送到服务端S后,服务端一看报文的源地址是C便直接把响应报文返回给C,即此时响应报文的源和目的地址对是(S,C)。这与客户端期待的报文源和目的地址对不匹配,客户端收到后会简单丢弃该报文。
因此,当报文不直接送达后端服务器,而是访问虚IP,经过一次中间网关(不管是虚拟网关还是实际网关)时,都需要在网关处做一次SNAT把报文的源IP修改成网关IP地址,以便回程报文回到该网关。再让该网关把回程报文目的修改成客户端(C)的IP地址,源地址改成虚IP。
IPVS模式
IPVS是LVS的负载均衡模块,基于netfilter的散列表,比iptables性能更高,具备更好的可扩展性。Kube-proxy的IPVS模式在Kubernetes 1.11版本达到稳定。
IPVS是Linux内核实现的四层负载均衡,是LVS负载均衡模块的实现。IPVS支持TCP、UDP、SCTP、IPv4、IPv6等协议,也支持多种负载均衡策略,例如rr、wrr、lc、wlc、sh、dh、lblc等。IPVS通过persistent connection调度算法原生支持会话保持功能。
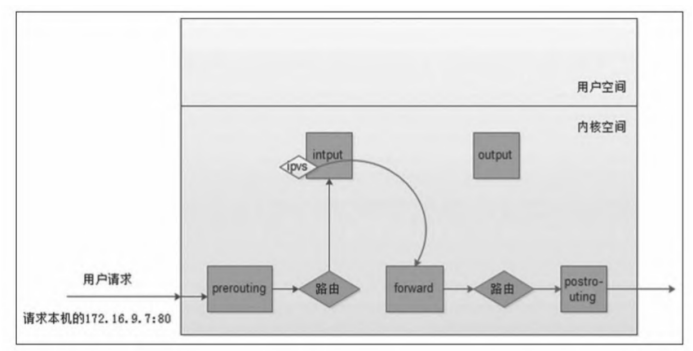
当外机的数据包首先经过netfilter的PREROUTING链,然后经过一次路由决策到达INPUT链,再做一次DNAT后经过FORWARD链离开本机网路协议栈。由于IPVS的DNAT发生在netfilter的INPUT链,因此如何让网路报文经过INPUT链在IPVS中就变得非常重要了。一般有两种解决方法,一种方法是把服务的虚IP写到本机的本地内核路由表中;另一种方法是在本机创建一个dummy网卡,然后把服务的虚IP绑定到该网卡上。Kubernetes使用的是第二种方法。
IPVS支持三种负载均衡模式:Direct Routing(简称DR)、Tunneling(也称ipip模式)和NAT(也称Masq模式)。
- DR模式是应用最广泛的IPVS模式,它工作在L2,即通过MAC地址做LB,而非IP地址。在DR模式下,回程报文不会经过IPVS Director而是直接返回给客户端。因此,DR在带来高性能的同时,对网络也有一定的限制,即要求IPVS的Director和客户端在同一个局域网内。另外,比较遗憾的是,DR不支持端口映射,无法支撑Kubernetes Service的所有场景。
- IPVS的Tunneling模式就是用IP包封装IP包,因此也称ipip模式。Tunneling模式下的报文不经过IPVS Director,而是直接回复给客户端。Tunneling模式同样不支持端口映射,因此很难被用在Kubernetes的Service场景中。
- IPVS的NAT模式支持端口映射,回程报文需要经过IPVS Director,因此也称Masq(伪装)模式。Kubernetes在用IPVS实现Service时用的正是NAT模式。当使用NAT模式时,需要注意对报文进行一次SNAT,这也是Kubernetes使用IPVS实现Service的微秒(tricky)之处。
注:虽然有些版本的IPVS,例如华为和阿里自己维护的分支支持fullNAT,即同时支持SNAT和DNAT,但是Linux内核原生版本的IPVS只做DNAT,不做SNAT。因此,在Kubernetes Service的某些场景下仍需要iptables。
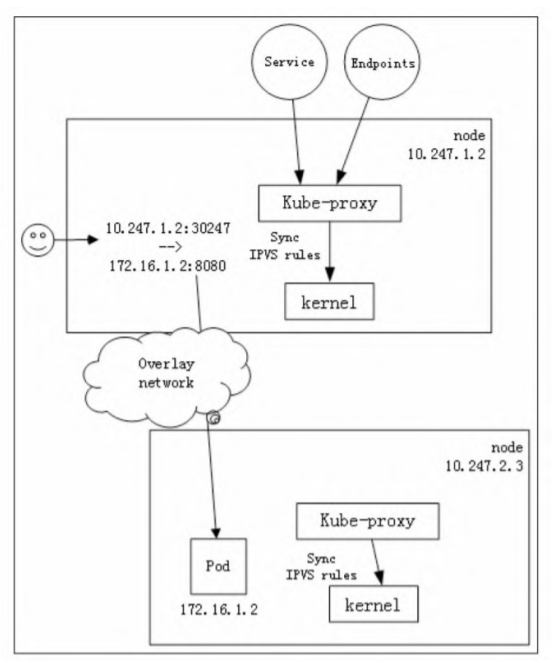
一旦创建一个Service和Endpoints,IPVS模式的Kube-proxy会做以下三件事情。
- 确保一块dummy网卡(kube-ipvs0)存在。IPVS的netfilter钩子挂载INPUT链,需要把Service的访问IP绑定在dummy网卡上让内核“觉得”虚IP就是本机IP,进而进入INPUT链。
- 把Service的访问IP绑定在dummy网卡上。
- 通过socket调用,创建IPVS的virtual server和real server,分别对应Kubernetes的Service和Endpoints。
IPVS用于流量转发,它无法处理Kube-proxy中的其他问题,例如包过滤、SNAT等。具体来说,IPVS模式的Kube-proxy将在以下4种情况下依赖iptables:
- Kube-proxy配置启动参数masquerade-all=true,即集群中所有经过Kube-proxy的包都做一次SNAT;
- Kube-proxy启动参数指定集群IP地址范围;
- 支持Load Balancer类型的服务,用于配置白名单;
- 支持NodePort类型的服务,用于在包跨节点前配置MASQUERADE,类似于上文提到的iptables模式。
不想创建太多的iptables规则,因此使用ipset减少iptables规则,使得不管集群内有多少服务,IPVS模式下iptables规则的总数在5条以内。
Ingress
Kubernetes的Ingress资源对象是指授权入站连接到达集群内服务的规则集合。
Ingress是建立在Service之上的L7访问入口,它支持通过URL的方式将Service暴露到k8s集群外;支持自定义Service的访问策略;提供按域名访问的虚拟主机功能;支持TLS通信。