CNI是容器网络的标准化,试图通过JSON描述一个容器网络配置。
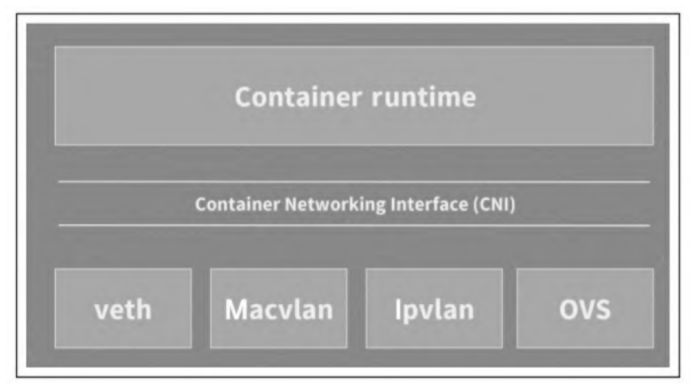
CNI是Kubernetes与底层网络插件之间的一个抽象层,为Kubernetes屏蔽了底层网络实现的复杂度,同时解耦了Kubernetes的具体网络插件实现。
CNI主要有两类接口:分别是在创建容器时调用的配置网络接口:
1
AddNetwork(net *NetworkConfig,rt* RuntimeConf)(types.Result,error)
和删除容器时调用的清理网络接口:
1
DelNetwork(net *NetworkConfig,rt* RuntimeConf)
两个入参分别是网络配置和runtime配置(容器运行时传入的网络namespace信息)。
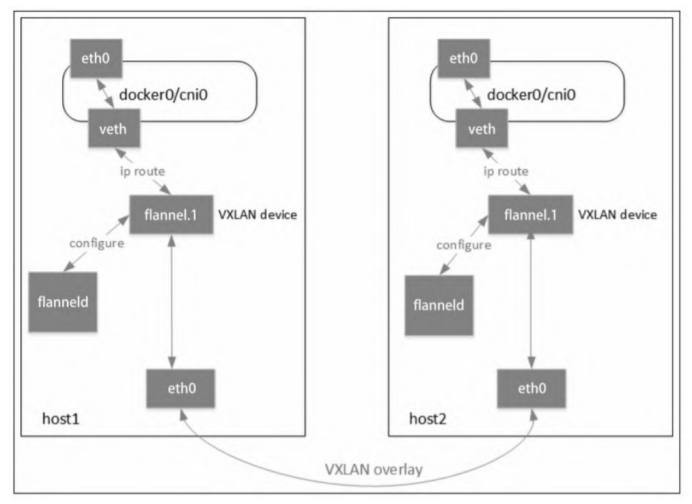
flannel
flannel的设计目的是为集群中的所有节点重新规划IP地址的使用规则,从而使得集群中的不同节点主机创建的容器都具有全集群“唯一”且“可路由的IP地址”,并让属于不同节点上的容器能够直接通过内网IP通信。
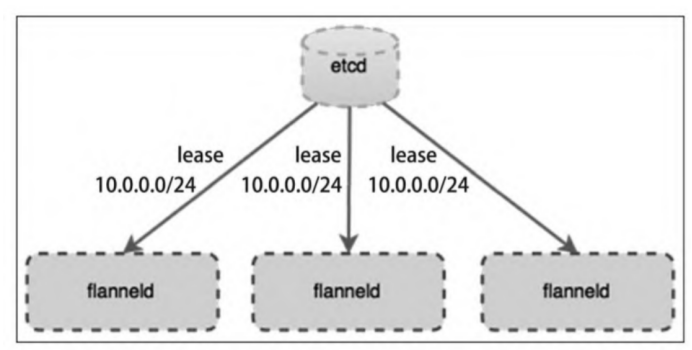
flannel在架构上分为管理面和数据面。管理面主要包含一个etcd,用于协调各个节点上容器分配的网段,数据面即在每个节点上运行一个flanneld进程。与其他网络方案不同的是,flannel采用的是no server架构,即不存在所谓的控制节点,简化了flannel的部署与运维。 集群内所有flannel节点共享一个大的容器地址段(例如10.0.0.0/16),flanneld一启动便会观察etcd,从etcd得知其他节点上的容器已占用的网段信息,然后向etcd申请该节点可用的IP地址段(在大网段中划分一个,例如10.0.2.0/24),并把该网段和主机IP地址等信息都记录在etcd中。
底层实现
flannel的底层实现实质上是一种overlay网络(除了Host-Gateway模式),即把某一协议的数据包封装在另一种网络协议中进行路由转发。flanneld会观察etcd的数据,因此在其他节点向etcd更新网段和主机IP信息时,etcd就感知到了,在向其他主机上的容器转发网络包时,用对方容器所在主机的IP进行封包,然后将数据发往对应主机上的flanneld,再交由其转发给目的容器。
flannel(v0.7+)目前已经支持的底层实现有:
- UDP
- VXLAN
- Alloc
- Host-Gateway
- AWS VPC
- GCE路由
其中,性能最好的应该是Host-Gateway。
安装配置
flanneld要先于Docker启动。flanneld启动时主要做了以下几个动作:
- 从etcd中获取network(大网)的配置信息;
- 划分subnet(子网),并在etcd中进行注册;
- 将子网信息记录到flannel维护的/run/flannel/subnet.env文件中;
backend详解
flannel通过在每一个节点上启动一个叫flanneld的进程,负责每一个节点上的子网划分,并将相关的配置信息(如各个节点的子网网段、外部IP等)保存到etcd中(flanneld的配置文件以ConfigMap的形式挂载到容器内的/etc/kube-flannel/目录),而具体的网络包转发交给具体的backend实现。 flanneld可以在启动时通过配置文件指定不同的backend进行网络通信,目前比较成熟的backend有UDP、VXLAN和Host Gateway三种。目前,VXLAN是官方最推崇的一种backend实现方式;Host Gateway一般用于对网络性能要求比较高的场景,但需要基础网络架构的支持;UDP则用于测试及一些比较老的不支持VXLAN的Linux内核。
UDP
当采用UDP模式时,flanneld进程在启动时会通过打开/dev/net/tun的方式生成一个tun设备(Linux中提供的一种内核网络与用户空间通信的机制,即应用可以通过直接读写tun设备的方式收发RAW IP包。)。
flanneld进程启动后,通过ip addr命令可以发现节点中已经多了一个叫flannel0的网络接口,通过ip -d link show flannel0可以看到这是一个tun设备。
本机通信实践:
当容器A发送到同一个subnet的容器B时,因为二者处于同一个子网,所以容器A和B位于同一个宿主机host上,而容器A和B也均桥接在docker0上。借助网桥docker0,即可实现同一个主机上容器A和B的直接通信。
注:较早版本的flannel是直接复用Docker创建的docker0网桥,后面版本的flannel将使用CNI创建自己的cni0网桥。不管是docker0还是cni0,本质都是Linux网桥,功能也一样。
跨主机通信实践:
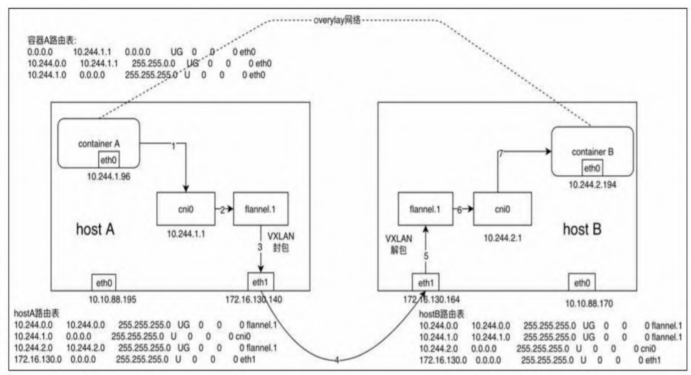
假设在节点A上有容器A(10.244.1.96),在节点B上有容器B(10.244.2.194)
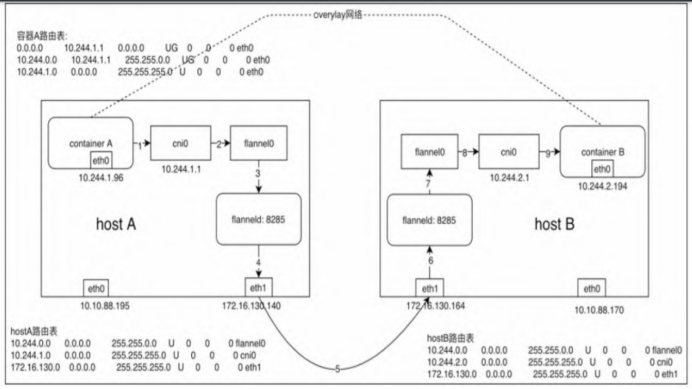
- 容器A发出ICMP请求报文,通过IP封装后的形式为10.244.1.96(源)→10.244.2.194(目的)。此时,通过容器A内的路由表匹配到应该将IP包发送到网关10.244.1.1(cni0网桥)。

- 到达cni0的IP包目的地IP 10.244.2.194,匹配到节点A上第一条路由规则(10.244.0.0),内核通过查本机路由表知道应该将RAW IP包发送给flannel0接口。
- flannel0为tun设备,发送给flannel0接口的RAW IP包(无MAC信息)将被flanneld进程接收,flanneld进程接收RAW IP包后在原有的基础上进行UDP封包,UDP封包的形式为172.16.130.140:{系统管理的随机端口}→172.16.130.164:8285。
注:172.16.130.164是10.244.2.194这个目的容器所在宿主机的IP地址,flanneld通过查询etcd很容易得到,8285是flanneld监听端口。
- flanneld将封装好的UDP报文经eth0发出,从这里可以看出网络包在通过eth0发出前先是加上了UDP头(8个字节),再加上IP头(20个字节)进行封装,这也是flannel0的MTU要比eth0的MTU小28个字节的原因,即防止封包后的以太网帧超过eth0的MTU,而在经过eth0时被丢弃。

- 网络包经过主机网络从节点A到达节点B。
- 主机B收到UDP报文后,Linux内核通过UDP端口号8285将包交给正在监听的flanneld。
- 运行在host B中的flanneld将UDP包解封包后得到RAW IP包:10.244.1.96→10.244.2.194。
- 解封包后的RAW IP包匹配到主机B上的路由规则(10.244.2.0),内核通过查本机路由表知道应该将RAW IP包发送到cni0网桥。

- cni0网桥将IP包转发给连接在该网桥上的容器B,就像上文提到的本机容器通信一样,由docker0转发到目标容器,至此整个流程结束。回程报文将按上面的数据流原路返回。
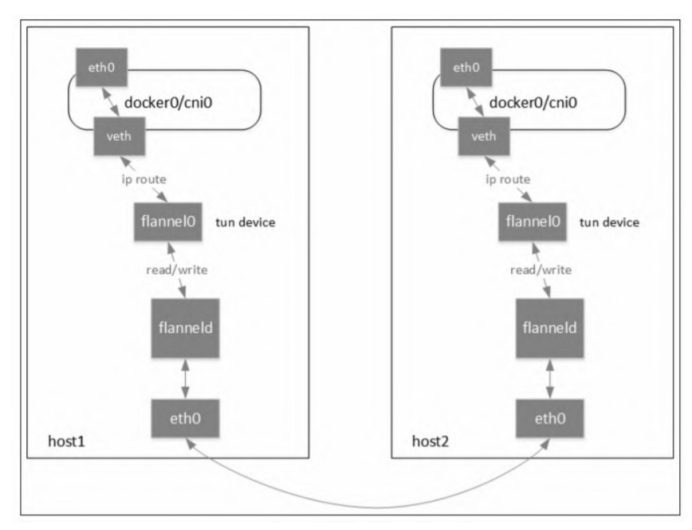
flanneld在其中主要起到的作用是:
- UDP封包解包;
- 节点上的路由表的动态更新。
网络数据包先通过tun设备从内核中复制到用户态,再由用户态的应用复制到内核,仅一次网络传输就进行了两次用户态和内核态的切换,显然效率是不高的。Linux内核本身也提供了比较成熟的网络封包/解包(隧道传输)实现方案VXLAN。
VXLAN
flannel对VXLAN的使用比较简单,因为目前Kubernetes只支持单网络,故在三层网络上只有1个VXLAN网络。因此,flannel会在集群的节点上新创建一个名为flannel.1(命名规则为flannel.[VNI],VNI默认为1)的VXLAN网卡。VTEP的MAC地址不是通过组播学习的,而是通过从API Server处watch Node发现的。 通过ip -d link查看VTEP设备flannel.1的配置信息:
1
2
3
4
5
# ip -d link show flannel.1
...
5: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdics noqueue state UNKNOWN mode DEFAULT
link/ether a2:5e:b0:43:09:a7 brd ff:ff:ff:ff:ff:ff promiscuity 0
VXLAN id 1 local 172.17.130.244 dev eth1 srcport 0 0 dstport 8472 nolearning ageing 300 addrgenmode eui64
可以看到,flannel.1配置的local IP为172.17.130.244(容器网段),flanneld为VXLAN外部UDP包目的端口配置的是Linux VXLAN默认端口8472,而不是IANA分配的4789端口。
flanneld启动时先确保VTEP设备(默认为flannel.1)已存在,若已经创建则跳过,并将VTEP设备的相关信息上报到etcd中,当在flannel网络中有新的节点加入集群并向etcd注册时,各个节点上的flanneld从etcd得知通知,并依次执行以下流程:
- 在节点中创建一条该节点所属网段的路由表,主要是能让Pod中的流量路由到flannel.1接口。通过route-n可以查看到节点上相关的路由信息:
1
2
3
4
5
6
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
172.17.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.17.1.0 172.17.1.0 255.255.255.0 UG 100 0 0 flannel.1
172.17.2.0 172.17.2.0 55.255.255.0 UG 100 0 0 flannel.1
- 在节点中添加一条该节点的IP及VTEP设备的静态ARP缓存。
1
2
3
# arp -n
172.17.1.3 dev flannel.1 lladdr 42:7f:69:c7:cd:37 STALE
172.17.2.4 dev flannel.1 lladdr 7a:2c:d0:7f:48:3f STALE
通过bridge命令查看节点上的VXLAN转发表(FDB entry),可以看到已经有两条转发表,
1
2
3
# bridge fdb show dev flannel.1
42:7f:69:c7:cd:37 dst 192.168.130.164 self permanent
7a:2c:d0:7f:48:3f dst 192.168.130.140 self permanent
其中MAC为对端容器的MAC,IP为对端VTEP的对外IP。flannel VTEP的对外IP地址可通过flanneld的启动参数-iface=eth0指定,若不指定则按默认网关查找网络接口对应的IP。 查看VXLAN的端口是8472:
1
2
# netstate -ulnp|grep 8472
upd 0 0 0.0.0.0:8470 0.0.0.0:* -
需要注意的是,上面输出的最后一栏显示的不是进程的ID和名称,而是一个破折号“-”,这说明8472这个UDP端口不是由用户态的进程监听的,而是flannel的VXLAN模式工作在内核态下。
- 同UDP Backend模式,容器A中的IP包通过容器A内的路由表被发送到cni0。
- 到达cni0中的IP包通过匹配host A中的路由表发现通往10.244.2.194的IP包应该交给flannel.1接口。
- flannel.1作为一个VTEP设备,收到报文后将按照VTEP的配置进行封包。首先,通过etcd得知10.244.2.194属于节点B,并得到节点B的IP。然后,通过节点A中的转发表得到节点B对应的VTEP的MAC,根据flannel.1设备创建时的设置参数(VNI、local IP、Port)进行VXLAN封包。
- 通过host A跟host B之间的网络连接,VXLAN包到达host B的eth1接口。
- 通过端口8472,VXLAN包被转发给VTEP设备flannel.1进行解包。
- 解封装后的IP包匹配host B中的路由表(10.244.2.0),内核将IP包转发给cni0。
- cni0将IP包转发给连接在cni0上的容器B。
在VXLAN模式下,数据是由内核转发的,flannel不转发数据,仅动态设置ARP和FDB表项。
Host Gateway
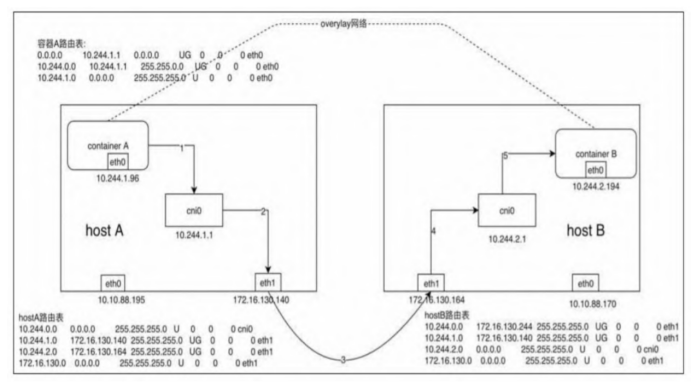
- 同UDP、VXLAN模式一致,通过容器A的路由表IP包到达cni0。
- 到达cni0的IP包匹配到host A中的路由规则(10.244.2.0),并且网关为172.16.130.164,即host B,所以内核将IP包发送给host B(172.16.130.164)。
- IP包通过物理网络到达host B的eth1。
- 到达host B eth1的IP包匹配到host B中的路由表(10.244.2.0),IP包被转发给cni0。
- cni0将IP包转发给连接在cni0上的容器B。 host-gw模式下,各个节点之间的跨节点网络通信要通过节点上的路由表实现,因此必须要通信双方所在的宿主机能够直接路由。这就要求flannel host-gw模式下集群中所有的节点必须处于同一个网络内,这个限制使得host-gw模式无法适用于集群规模较大且需要对节点进行网段划分的场景。host-gw的另外一个限制则是随着集群中节点规模的增大,flanneld维护主机上成千上万条路由表的动态更新也是一个不小的压力,因此在路由方式下,路由表规则的数量是限制网络规模的一个重要因素。
Calico
Calico是一个基于BGP的纯三层的数据中心网络方案(也支持overlay网络)。三层通信模型表示每个容器都通过IP直接通信,中间通过路由转发找到对方。在这个过程中,容器所在的节点类似于传统的路由器,提供了路由查找的功能。要想路由能够正常工作,每个容器所在的主机节点扮演了虚拟路由器(vRouter)的功能。
到flannel的host-gw模式之所以不能跨二层网络,是因为它只能修改主机的路由,Calico把改路由表的做法换成了标准的BGP路由协议。相当于在每个节点上模拟出一个额外的路由器,由于采用的是标准协议,Calico模拟路由器的路由表信息可以被传播到网络的其他路由设备中,这样就实现了在三层网络上的高速跨节点网络。
注:现实中的网络并不总是支持BGP路由,因此Calico也设计了一种ipip模式,使用overlay的方式传输数据。ipip的包头非常小,而且是内置在内核中的,因此它的速度理论上要比VXLAN快,但是安全性更差。
Calico在每一个计算节点利用Linux内核的一些能力实现了一个高效的vRouter负责数据转发,而每个vRouter通过BGP把自己运行的工作负载的路由信息向整个Calico网络传播。
架构
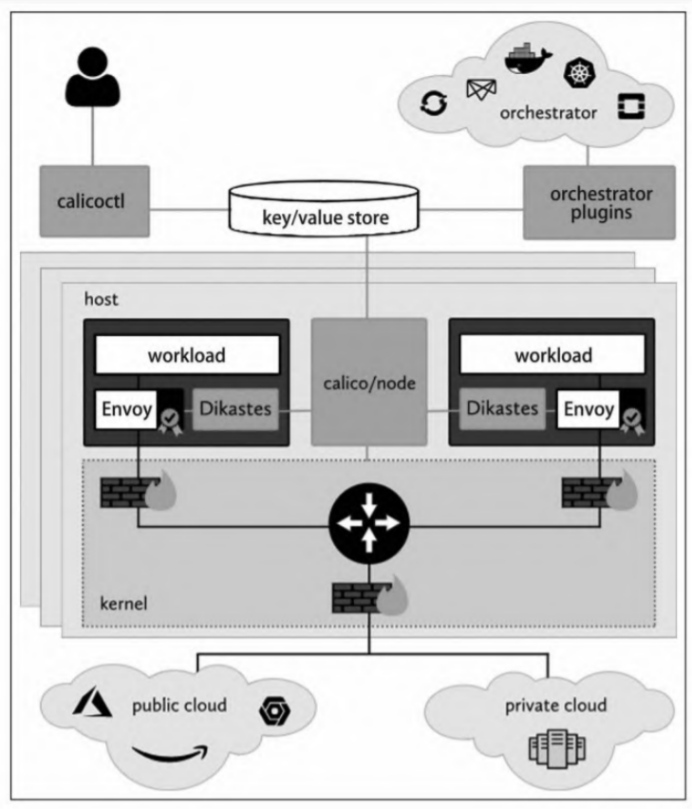
- calicoctl:Calico的命令行工具,允许从命令行界面配置实现高级策略和网络;
- orchestrator plugins:提供与各种流行的云计算编排工具的紧密集成和同步支持;
- key/value store:存储Calico的策略配置和网络状态信息,目前主要使用etcdv3或Kubernetes API Server;
- calico/node:在每个主机上运行的agent,从key/value存储中读取相关的策略和网络配置信息,并在Linux内核中实现;
- Dikastes/Envoy:可选的Kubernetes sidecar,可以通过相互TLS身份验证保护工作负载之间的通信安全,并动态配置应用层控制策略。
组件
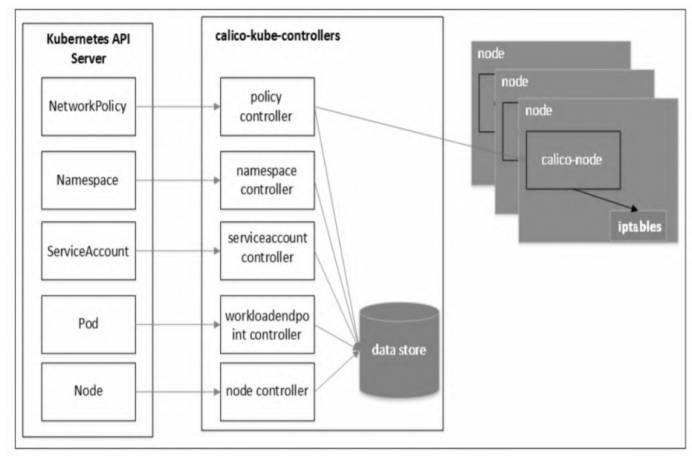
calico-kube-controllers
整个集群环境只有一个以calico-kubecontrollers开头命名的Pod,用于从Kubernetes API Server中读取NetworkPolicy等信息,并对Calico进行相应的配置。
- policy controller:监视Kubneters的NetworkPolicy对象并编程Calico策略。policy controller会把Kubernetes的NetworkPolicy对象同步到Calico的数据库中,因此需要有对Kubernetes API的读权限,以监听NetworkPolicy的增删改查事件。用户在Kubernetes集群中配置了Pod网络策略后,policy controller就会通知各个节点上的calico-node服务,在主机上刷新相应的iptables规则,完成对Pod间网络的隔离。
- namespace controller:监视Kubernetes的Namespace对象并刷新Calico配置文件,它会把Kubernetes的namespace label变化同步到Calico的数据库中。
- serviceaccount controller:监视Kubernetes的ServiceAccount对象和刷新Calico配置文件,它会把Kubernetes的ServiceAccount变化同步到Calico的数据库中。
- workloadendpoint controller:监视Kubernetes Pod标签的更改并刷新Calico工作负载中的Endpoints配置,它会把Kubernetes的Pod label变化同步到Calico的数据库中。
- node controller:监视Kubernetes Node的删除动作并从Calico数据库中删除相应的数据。
calico-node
在集群的每个节点上都会运行一个以calico-node开头命名的Pod,通过配置iptables实现节点上Pod的出/入(ingress/egress)网络策略。calico-node通常以Kubernetes DaemonSet方式部署运行。
注:
- 除了node controller,其他功能的控制器均是默认启用的。如果直接使用Calico提供的manifest部署calico-kube-controllers容器,则仍然通过配置ENABLED_CONTROLLERS选项打开node controller控制器。启用node controller控制器,还需要在calico-node DaemonSet的manifest文件中添加一个环境变量CALICO_K8S_NODE_REF,取值为nodeName。
- 以上所有的控制器都是仅在使用etcd作为Calico后端数据存储时才有效。
- 为了使calico-kube-controllers不受容器网络访问控制策略的阻止,calico-kube-controllers容器必须使用主机网络,即在Pod的manifest配置hostNetwork:true。
隧道模式
和其他overlay模式一样,ipip是在各节点之间“架起”一个隧道,通过隧道两端节点上的容器网络连接,实现机制简单说就是用IP包头封装原始IP报文。启用ipip模式时,Calico将在各个节点上创建一个名为tunl0的虚拟网络接口。
报文路径
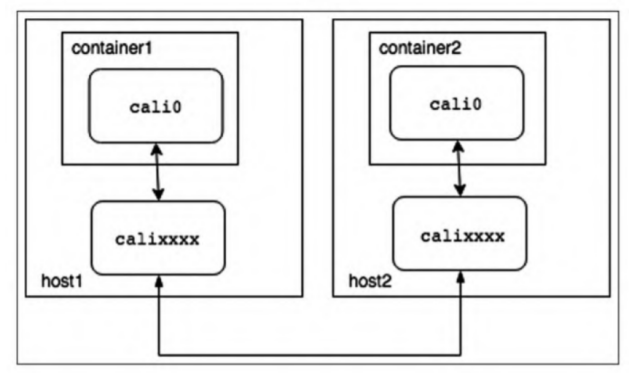
Calico为所有容器分配的容器MAC地址都一样,这么做是因为Calico只关心三层的IP地址,根本不关心二层MAC地址。
容器1会查自己的路由表获取下一跳的地址,所有的报文都会经过cali0发送到下一跳169.254.1.1(这是预留的本地IP网段)。Calico为了简化网络配置将容器里的路由规则都配置成一样的,不需要动态更新。cali0是veth pair的一端,其另一端是主机上以caliXXXX命名的网卡。
主机上index的网卡卡被分配了一个随机的MAC地址,但是没有IP地址。容器的后续报文IP地址还是目的容器,但是MAC地址就变成了主机上该网卡的地址。即所有的报文都会发给主机,主机根据IP地址再进行转发。
总的来说,可以认为Calico把主机作为容器的默认网关使用,所有的报文发到主机,主机根据路由表进行转发。和经典的网络架构不同的是,Calico并没有给默认网关配置一个IP地址,而是通过“ARP proxy”和修改容器路由表的机制实现。
主机上的calico-xxxx网卡接收到报文之后,所有的报文会根据路由表转发,并通过主机的eth0网卡发出。
注:在发送到另一台主机之前,报文还会经过Calico配置的iptables规则。如果被iptables规则拦住,包就会被内核丢弃。
报文到达容器所在的主机,主机上的每个容器都会有一个对应的路由表项。报文被发送到veth pair,然后从另一端发送给目标容器。目标容器接收到报文之后,回复ICMP报文,应答报文原路返回。
为什么Calico网络选择BGP
- BGP是一种简单的路由协议。
- 拥有当前行业的最佳实践。
- 唯一能够支撑Calico网络规模的协议。
缺点
Calico路由的数目与容器数目相同,极易超过三层交换、路由器或节点的处理能力,从而限制了整个网络的扩张,因此Calico网络的瓶颈在于路由信息的容量。Calico会在每个节点上设置大量的iptables规则和路由规则,这将带来极大的运维和故障排障难度。Calico的原理决定了它不可能支持VPC,容器只能从Calico设置的网段中获取IP。