map又被称为哈希表,是使用频率极高的一种数据结构。哈希表的原理是将多个键/值(key/value) 对分散存储在buckets (桶)中。给定一个键(key), 哈希(Hash) 算法会计算出键值对存储的位置。
哈希碰撞与解决方法
Go语言中的哈希表采用的是开放寻址法中的线性探测(Linear Probing)策略,线性探测策略是顺序(每次探测间隔为1)的。
开放寻址法(Open Addressing) :所有元素都存储在桶的数组中。当必须插入新条目时,将按某种探测策略操作,直到找到未使用的数组插槽为止。当搜索元素时,将按相同顺序扫描存储桶,直到查找到目标记录或找到未使用的插槽为止。
基本操作
map声明与初始化
map 的第一种声明方式如下:
1
var hash map[T]T
其并未对map进行初始化操作,值为nil,因此一旦进行hash[key]=value这样的赋值操作就会报错。
1
panic(plainError("assignment to entry in nil map"))
比较意外的是,Go语言允许对值为nil的 map进行访问,虽然结果毫无意义。 map的第二种声明方式是通过make 函数初始化。make函数中的第二个参数代表初始化创建map的长度,当NUMBER为空时,其默认长度为0。
1
var hash = make (map [T]T, NUMBER)
此种方式可以正常地对map进行访问与赋值。map还有字面量形式初始化的方式,如下所示,country与rating在创建map时即在其中添加了元素。
1
2
3
4
5
6
7
8
var country = map[string]string{
"China": "Beijing",
"Japan": "Tokyo",
"India": "New Delhi",
"France": "Paris",
"Italy": "Rome",
}
rating := map[string]float64{"c": 5, "Go": 4.5, "Python": 4.5, "C++": 3}
访问
1
2
v := hash[key]
v, ok := map[key]
当返回两个参数时,第2个参数代表当前key在map中是否存在。
map赋值
hash[key]=value代表将value与map1哈希表中的key绑定在一起。
delete是Go语言中的关键字,用于进行map的删除操作,形如delete(hash,key),可以对相同的key进行多次删除操作而不会报错。
哈希表底层结构
1
2
3
4
5
6
7
8
9
10
11
type hmap struct{
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
- count代表map中元素的数量。
- flags代表当前map的状态(是否处于正在写入的状态等)。
- 2的B次幂表示当前map中桶的数量,2^B=Buckets size。
- noverflow为map中溢出桶的数量。当溢出的桶太多时,map会进行same-size map growth,其实质是避免溢出桶过大导致内存泄露。
- hash0代表生成hash的随机数种子。
- buckets是指向当前map对应的桶的指针。
- oldbuckets是在map扩容时存储旧桶的,当所有旧桶中的数据都已经转移到了新桶中时,则清空。
- nevacuate在扩容时使用,用于标记当前旧桶中小于nevacuate的数据都已经转移到了新桶中。
- extra存储map中的溢出桶。
1
2
3
4
5
type bmap struct{
tophash [bucketCnt]uint8 //一个固定长度为8的数组。此字段顺序存储key的哈希值的前8位。
key [bucketCnt]T
value [bucketCnt]T
}
map在编译时即确定了map中key、value 及桶的大小,因此在运行时仅仅通过指针操作就可以找到特定位置的元素。桶在存储的tophash字段后,会存储key数组及value数组。
哈希表原理图解
Go语言选择将key与value分开存储而不是以key/value/key/value的形式存储,是为了在字节对齐时压缩空间。
在进行hash[key]的 map访问操作时,会首先通过hash算法找到桶的位置,找到桶的位置后遍历tophash数组,如果在数组中找到了相同的hash,那么可以接着通过指针的寻址操作找到对应的key与value。
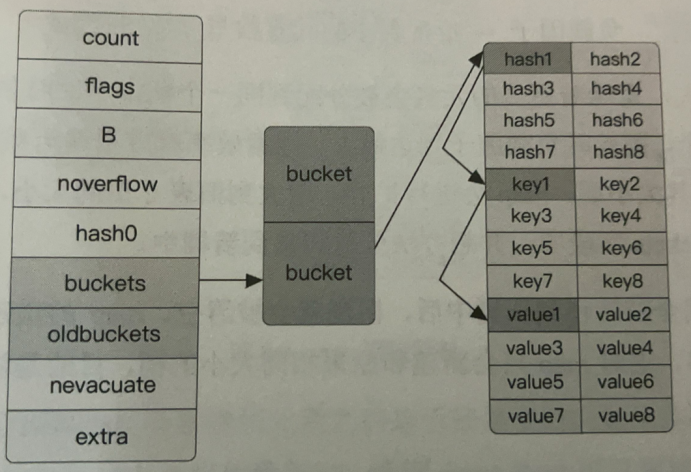 在Go语言中还有一个溢出桶的概念,在执行hash[key]=value赋值操作时,当指定桶中的数据超过8个时,并不会直接开辟一个新桶,而是将数据放置到溢出桶中,每个桶的最后都存储了overflow,即溢出桶的指针。在正常情况下,数据是很少会跑到滥出桶里面去的。同理,在map执行查找操作时,如果key的hash在指定桶的tophash数机中不存在,那么需要遍历滥出桶中的数据。
在Go语言中还有一个溢出桶的概念,在执行hash[key]=value赋值操作时,当指定桶中的数据超过8个时,并不会直接开辟一个新桶,而是将数据放置到溢出桶中,每个桶的最后都存储了overflow,即溢出桶的指针。在正常情况下,数据是很少会跑到滥出桶里面去的。同理,在map执行查找操作时,如果key的hash在指定桶的tophash数机中不存在,那么需要遍历滥出桶中的数据。
如果一开始,初始化map的数量比较大,则map会提前创建好一些溢出桶存储在extra *mapextra字段。
1
2
3
4
5
type mapextra struct {
overflow *[]*bmap
oldOverflow *[]*bmap
nextOverflow *bmap
}
当出现溢出现象时,可以用提前创建好的桶而不用申请额外的内存空间。只有预分配的溢出桶使用完了,才会新建溢出桶。
当发生以下两种情况之一时,map 会进行重建:
- map 超过了负载因子大小。
在哈希表中有经典的负载因子的概念:负载因子 = 哈希表中的元素数量 / 桶的数量
负载因子的增大,意味着更多的元素会被分配到同一个桶中,此时效率会减慢。Go语言中的负载因子为6.5,当超过其大小后,map会进行扩容,增大到旧表2倍的大小,旧桶的数据会存到oldbuckets字段中,并想办法分散转移到新桶中。当旧桶中的数据全部转移到新桶中后,旧桶就会被清空。
-
溢出桶的数量过多。
-
map只会新建和原来相同大小的桶,目的是防止溢出桶的数量缓慢增长导致的内存泄露。
当进行map的delete操作时,和赋值操作类似,delete 操作会根据key找到指定的桶,如果存在指定的key,那么就释放掉key与value引用的内存。同时tophash中的指定位置会存储emptyOne,代表当前位置是空的。
总结
指定了map的长度N,则在初始化时会生成桶,桶的数量为log2N。如果map的长度大于24,则会在初始化时生成溢出桶。溢出桶的数量为2^(B-4),其中,B为桶的数量。
在涉及访问、赋值、删除操作时,会首先计算出数据的hash值,然后进行简单的&运算计算出数据存储在桶中的位置,接着将hash值的前8位与存储在桶中的hash和key进行比较,最后完成赋值与访问操作。
如果数据放不下了,则会申请放置到溢出桶中。如果map超过了负载因子大小,则会进行双倍重建,如果溢出桶太大,则会进行等量重建。数据的转移采取了写时复制的规则,即在用到时才会将旧桶的数据打散放入新桶。